Współczesny świat biznesu rozwija się z każdą sekundą, co oznacza, że stale rośnie liczba krytycznych danych, które muszą być chronione. W razie katastrofy każda firma musi dysponować zestawem strategii odzyskiwania, aby jak najszybciej chronić i przywracać kluczowe procesy. W związku z tym pojawia się potrzeba zdalnej replikacji, która zakłada wysyłanie krytycznych danych biznesowych poza miejsce pracy w celu niezawodnego przechowywania i szybkiego odzyskiwania.
Co to jest replikacja zdalna?
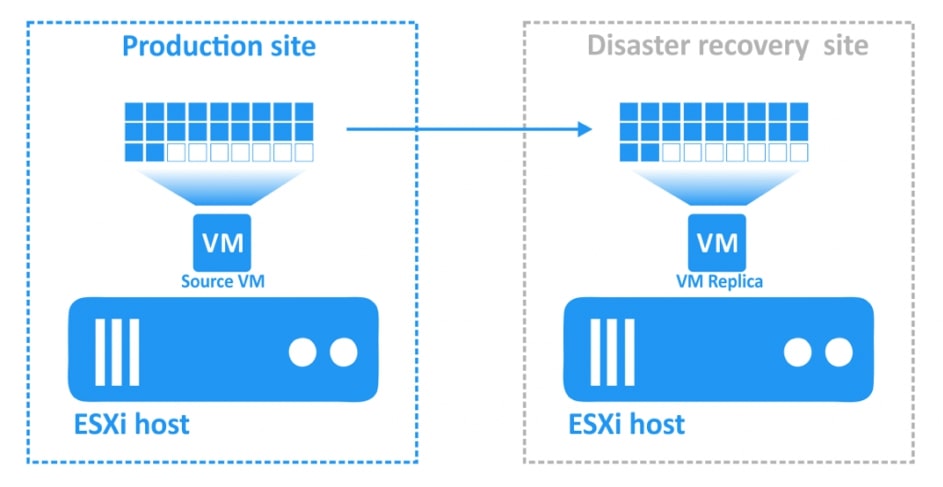
Zdalna replikacja jest istotną częścią ochrony i odzyskiwania danych. Wcześniej replikacja była najczęściej używana do kopiowania i przechowywania danych aplikacji w lokalizacjach poza siedzibą. Jednak z biegiem czasu technologia ta znacznie się rozszerzyła. Obecnie replikacja umożliwia utworzenie zsynchronizowanej kopii maszyny wirtualnej na zdalnym hoście docelowym. Kopia VM jest nazywana repliką i działa tak jak zwykła maszyna wirtualna dostępna na hoście źródłowym. Repliki VM można przenosić i uruchamiać na dowolnym, sprawnym sprzęcie. Mogą zostać włączone w ciągu kilku sekund w przypadku awarii oryginalnej maszyny wirtualnej. Technologia ta może znacznie zmniejszyć przestoje, a także ograniczyć potencjalne ryzyko biznesowe i straty związane z katastrofą.
Przed uruchomieniem zadania replikacji należy wziąć pod uwagę następujące czynniki:
- Odległość – im większa odległość między lokalizacjami, tym większe opóźnienie.
- Przepustowość – szybkość internetu i połączenie sieciowe powinny być wystarczające, aby zapewnić zaawansowane połączenie dla szybkiego i bezpiecznego transferu danych.
- Szybkość transmisji danych – szybkość transmisji danych powinna być niższa niż dostępna przepustowość, aby nie przeciążać sieci.
- Technologia replikacji – zadania replikacji powinny być uruchamiane równolegle (jednocześnie) w celu efektywnego wykorzystania sieci.
Czynniki te pomagają określić, który typ replikacji jest lepszy, gdy mamy do czynienia z określonym rodzajem katastrofy.
Strategie replikacji
Można wyróżnić dwa główne typy replikacji danych: synchroniczne i asynchroniczne.
Replikacja synchroniczna
W tym przypadku dane są replikowane do dodatkowej lokalizacji zdalnej w tym samym czasie, gdy nowe dane są tworzone lub aktualizowane w głównym centrum danych. Umożliwia to niemal natychmiastową replikację, co pozwala zachować repliki danych zaledwie kilka minut starsze niż materiał źródłowy. Zasadniczo zarówno źródło hosta, jak i źródło docelowe pozostają całkowicie zsynchronizowane, co ma kluczowe znaczenie dla skutecznego przywracania systemu po awarii (DR).
Ze względu na to, że dane są atomowo aktualizowane w wielu lokalizacjach zdalnych, wpływa to na wydajność i dostępność sieci. Operacje atomowe są definiowane jako sekwencja operacji, które muszą być zakończone bez przerwy przed wykonaniem innego zadania. W kontekście synchronicznej replikacji oznacza to, że zapis jest uważany za zakończony tylko wtedy, gdy oba lokalne i zdalne magazyny potwierdzają jego zakończenie. Dlatego gwarantowana jest zerowa utrata danych, ale ogólna wydajność jest spowolniona.
Replikacja asynchroniczna
W takim przypadku replikacja nie jest wykonywana w tym samym czasie, co zmiany w pamięci podstawowej. Dane są replikowane tylko we wcześniej określonych przedziałach czasowych (może to być godzina, dzień lub tydzień). Replika może być przechowywana w zdalnej lokalizacji DR, ponieważ nie musi być synchronizowana z pierwotną lokalizacją w czasie rzeczywistym.
Przy replikacji asynchronicznej dane nie są aktualizowane atomowo w wielu lokalizacjach, co oznacza, że aplikacja kontynuuje pisanie danych, które nie są jeszcze w pełni zreplikowane. W związku z tym zapis uznaje się za zakończony, gdy tylko pamięć lokalna go potwierdza.
Replikacja asynchroniczna poprawia wydajność i dostępność sieci bez wpływu na przepustowość. Wynika to z faktu, że repliki nie są aktualizowane w czasie rzeczywistym. Minusem jest to, że w scenariuszu katastrofy strona DR może nie zawierać ostatnio wprowadzonych zmian, więc niektóre krytyczne dane mogą zostać utracone.
Replikacja synchroniczna vs. asynchroniczna: główne różnice
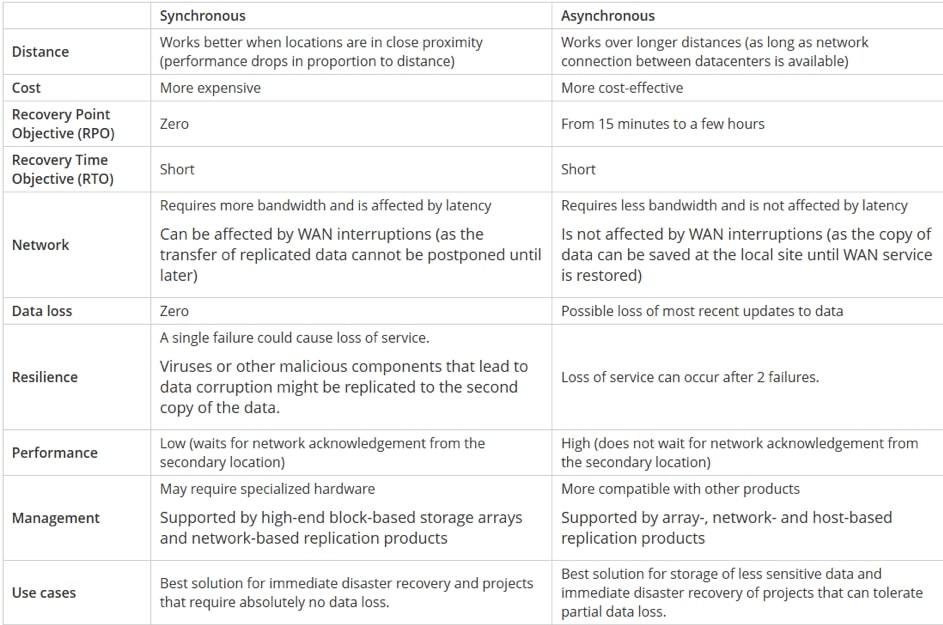
Co jest lepsze: replikacja synchroniczna lub asynchroniczna?
Na to pytanie nie ma jednoznacznej odpowiedzi; wybór zależy całkowicie od priorytetów biznesowych. Asynchroniczna replikacja działa najlepiej w przypadku projektów obejmujących duże odległości, którym przydzielony jest minimalny budżet. Jest także odpowiednia dla firm, które mogą sobie pozwolić na częściową utratę danych. Z drugiej strony replikacja synchroniczna jest wykonywana, gdy wymagane jest niezawodne i długoterminowe przechowywanie, a firma nie może pozwolić sobie na utratę krytycznych danych. Jest to przydatne, gdy RTO i RPO są krótkie.
Istnieje jednak pole pośrednie: można używać zarówno synchronicznych, jak i asynchronicznych strategii replikacji na różnych poziomach infrastruktury. Na przykład replikacja synchroniczna może być używana do przesyłania i zabezpieczania danych przez sieć lokalną (LAN), podczas gdy replikacja asynchroniczna wysyła krytyczne dane do zdalnej lokalizacji DR.
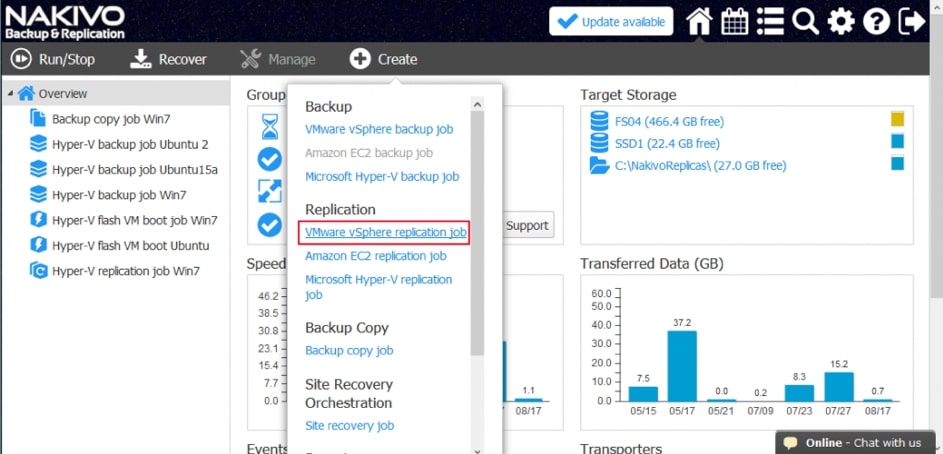
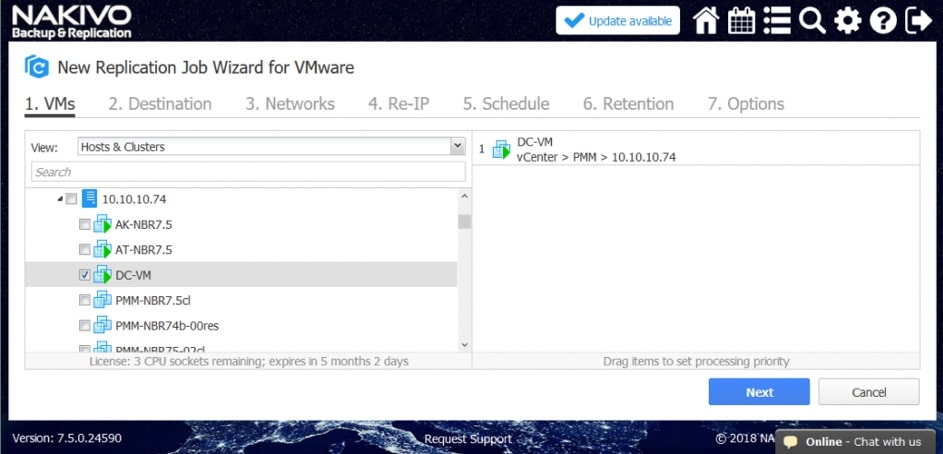
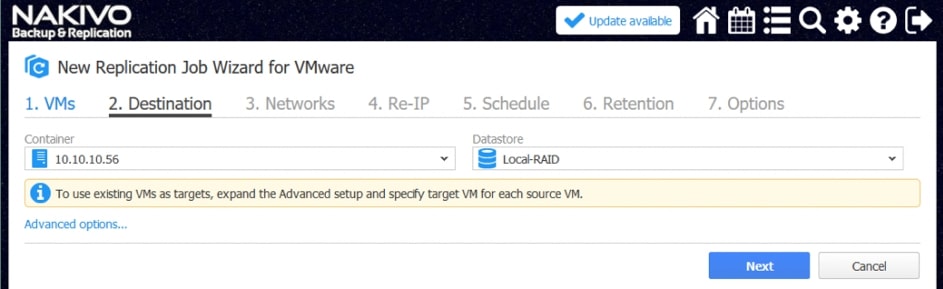
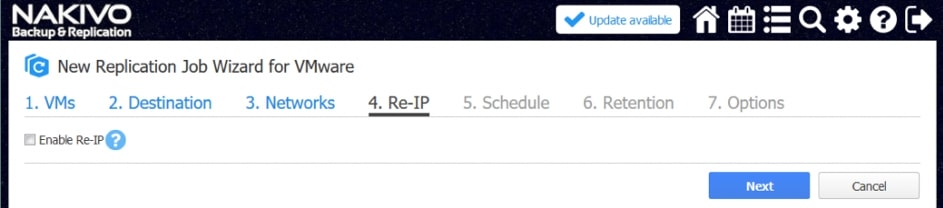
Replikacja w NAKIVO Backup&Replication
Tryb replikacji
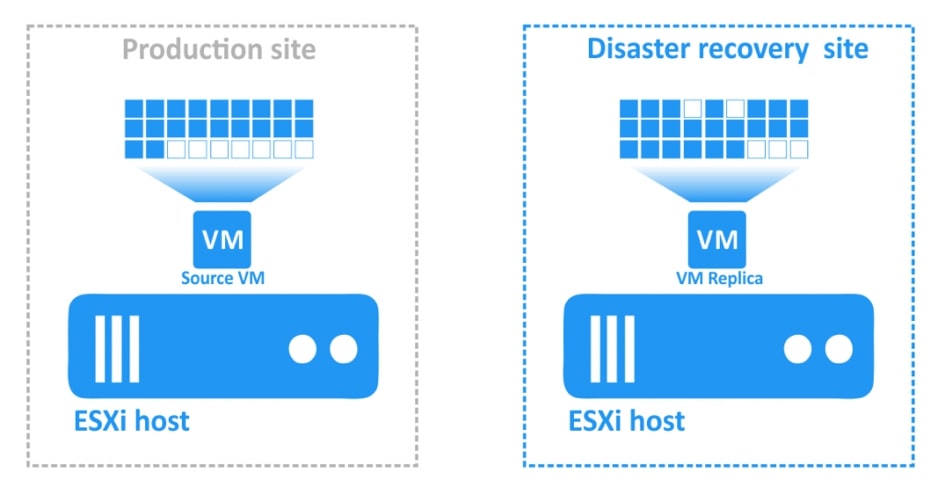
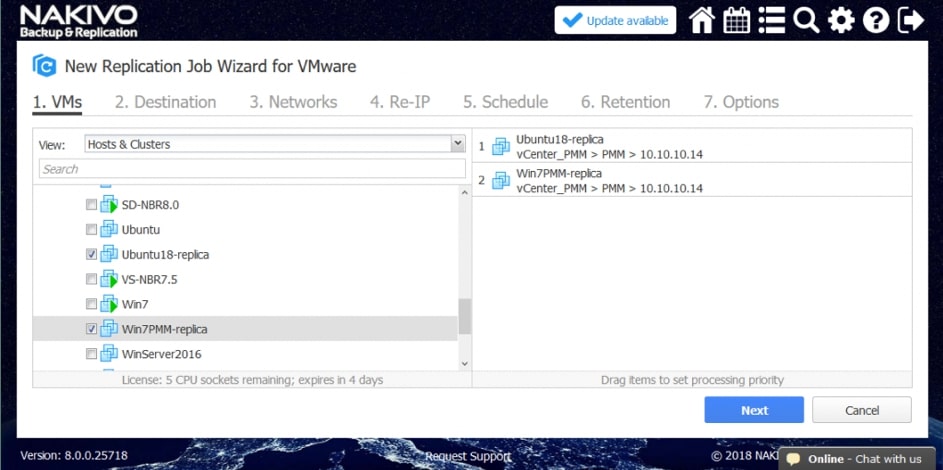
Replikacja w NAKIVO Backup&Replication jest zawsze przyrostowa . Pierwsza replikacja kopiuje pełną maszynę wirtualną, ale następujące zadania replikacji będą zapisywać tylko zmiany danych w replice (przyrostach). Ponadto po każdym zadaniu replikacji tworzony jest punkt odzyskiwania odwołujący się do wszystkich bloków danych wymaganych do odtwarzania maszyny wirtualnej. Ten tryb replikacji zapewnia mniejsze obciążenie sieci i oszczędza czas, który w innym przypadku zostałby poświęcony na pełne zadania replikacji.
Zgodne platformy
NAKIVO Backup & Replication oferuje szybkie wdrażanie na różnych platformach sprzętowych i programowych:
- VMware VA. Wstępnie skonfigurowany VMware Virtual Appliance można łatwo pobrać, a następnie zaimportować do VMware vSphere.
- Instalując NAKIVO Backup & Replication bezpośrednio na urządzeniu NAS, można stworzyć własne urządzenie do tworzenia kopii zapasowych VM.
- AWS AMI. Oprogramowanie NAKIVO Backup & Replication można wdrożyć w chmurze Amazon jako wstępnie skonfigurowany obraz Amazon Machine Image (AMI).
- Oprogramowanie NAKIVO Backup & Replication można zainstalować na fizycznej lub wirtualnej maszynie z systemem Linux za pomocą jednego polecenia.
- Oprogramowanie NAKIVO Backup & Replication można zainstalować na fizycznym lub wirtualnym komputerze z systemem Windows za pomocą jednego kliknięcia.
Funkcje replikacji
Migawki
Migawka rejestruje stan systemu w określonym momencie. Za pomocą NAKIVO Backup & Replication repliki VM są tworzone za pomocą migawek VM, które służą do pobierania aktualnych danych maszyn wirtualnych. Za każdym razem, gdy wykonywane jest zadanie replikacji, pobierana jest tymczasowa migawka maszyny wirtualnej, zmienione dane są identyfikowane, a wszystkie aktualizacje są dodawane do repliki. Po zakończeniu zadania migawka zostaje usunięta.
Changed block tracking
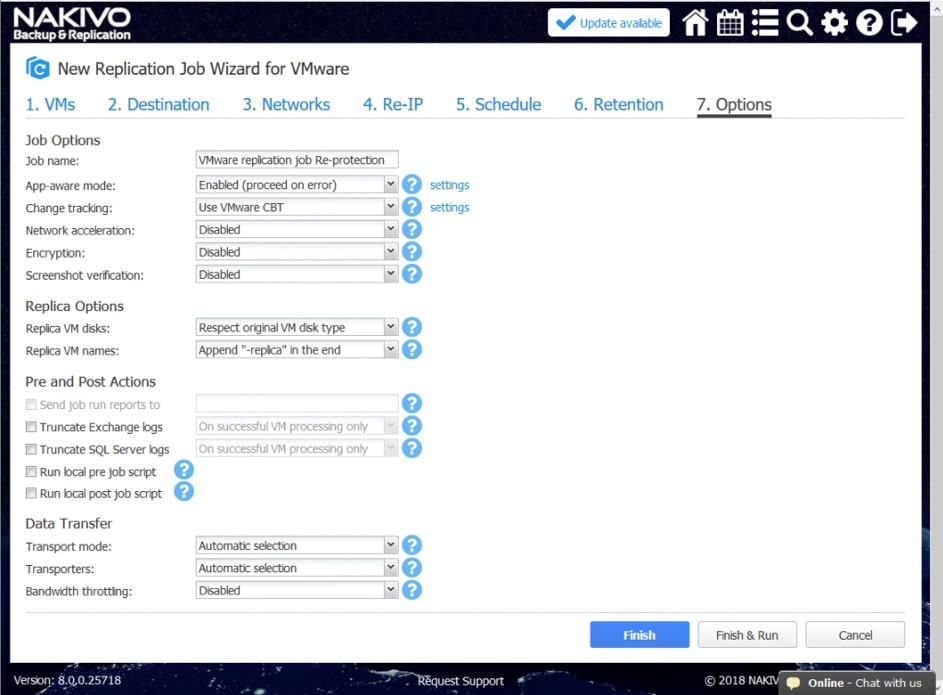
Oprogramowanie NAKIVO Backup & Replication wykorzystuje VMware CBT (Changed Block Tracking) i Hyper-V RCT (Resilient Change Tracking) do identyfikowania i kopiowania zmian, które zostały wprowadzone w maszynie wirtualnej od czasu ostatniej replikacji. Ta technologia znacząco poprawia szybkość replikacji. Jeśli CBT i RCT są niedostępne, NAKIVO Backup & Replication używa wbudowanej zastrzeżonej metody śledzenia zmian.
Obsługa aplikacji na żywo
NAKIVO Backup & Replication to rozwiązanie obsługujące aplikacje. Maszyny wirtualne są używane do uruchamiania wszelkiego rodzaju aplikacji o znaczeniu krytycznym, takich jak Microsoft Exchange, Active Directory, SQL, SharePoint itp. W przypadku tych programów z częstym wprowadzaniem i generowaniem danych istotne jest zapewnienie, że dane aplikacji są zawsze spójne, szczególnie gdy zadanie replikacji jest uruchomione. Tak więc po utworzeniu migawki aplikacje wewnątrz maszyny wirtualnej przechowują wszystkie transakcje w pamięci, aby nie zakłócać żadnych działających operacji.
Ochrona kontenera
Program NAKIVO Backup & Replication ułatwia ochronę krytycznych maszyn wirtualnych, umożliwiając ich uporządkowanie w kontenerach, takich jak pule zasobów, foldery lub klastry. Cały kontener można dodać do określonego zadania replikacji. Można łatwo dodawać lub usuwać elementy z kontenera, które to zmiany są automatycznie odzwierciedlane w odpowiednich zadaniach replikacji. Funkcja jest elastyczna; można również wykluczyć niektóre maszyny wirtualne z kontenera z zadania replikacji. W takim przypadku cały kontener zostanie objęty ochroną z wyjątkiem wykluczonych maszyn wirtualnych.
Screenshot verification
Ta funkcja umożliwia automatyczne sprawdzenie, czy replikacja maszyn wirtualnych zakończyła się pomyślnie. Zaraz po zakończeniu zadania replikacji sieć w replice jest wyłączona, a replika jest chwilowo włączona, aby wykonać zrzut ekranu. Replika jest następnie wyłączana i powracana do najnowszego punktu odzyskiwania. Użytkownik otrzymuje raport e-mail ze zrzutem ekranu z testowanego systemu operacyjnego.
Grupowanie zadań
NAKIVO Backup & Replication pozwala organizować zadania replikacji w grupy (foldery), aby rozmieścić aplikacje, usługi i lokalizacje w strukturach logicznych. Ponadto akcje zbiorcze można łatwo wykonać dla wszystkich lub wybranych zadań dla grupy.
Automatyczne raporty
Jeśli chcemy być informowani o statusie zadań replikacji, NAKIVO Backup & Replication może powiadomić nas o tym, wysyłając automatyczne raporty e-mailem, według harmonogramu lub na żądanie.
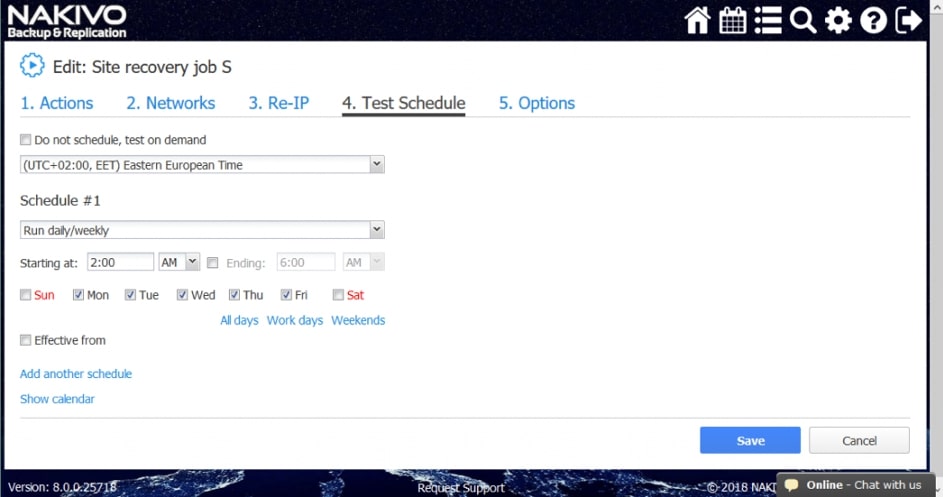
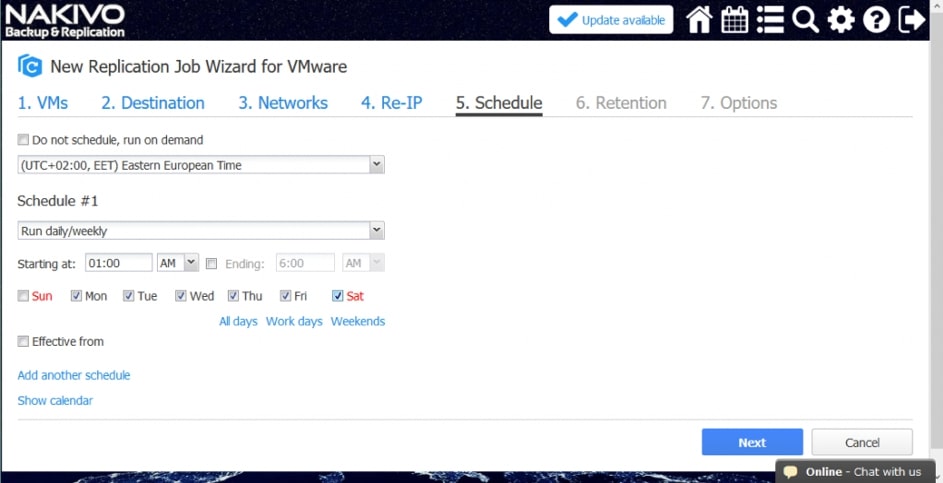
Harmonogram zadań
Program NAKIVO Backup & Replication umożliwia konfigurowanie zadań replikacji uruchamianych na żądanie lub zgodnie z harmonogramem (codziennie, co tydzień, co miesiąc i co rok). Możesz nawet skonfigurować zadania, aby działały według niestandardowego harmonogramu, który odpowiada konkretnym potrzebom biznesowym, np. co 20 minut, co 5 dni lub w pierwszy wtorek każdego miesiąca. Możesz także określić okna czasowe, w których zadanie powinno się rozpoczynać i kończyć.
Etapowa replikacja VM (wysiewanie)
Początkowa (pełna) replikacja większych maszyn wirtualnych może zająć dużo czasu ze względu na ich rozmiar. Aby przyspieszyć proces, NAKIVO Backup & Replication może przeprowadzić etapową replikację maszyn wirtualnych. Ta funkcja umożliwia przeniesienie (“seed”) początkowych replik VM na nośniki wymienne. Następnie repliki te można przetransportować do nowej witryny, gdzie nowe zadanie replikacji jest uruchamiane przy użyciu przesłanych maszyn wirtualnych. Następnie wykonywana jest tylko przyrostowa replikacja.
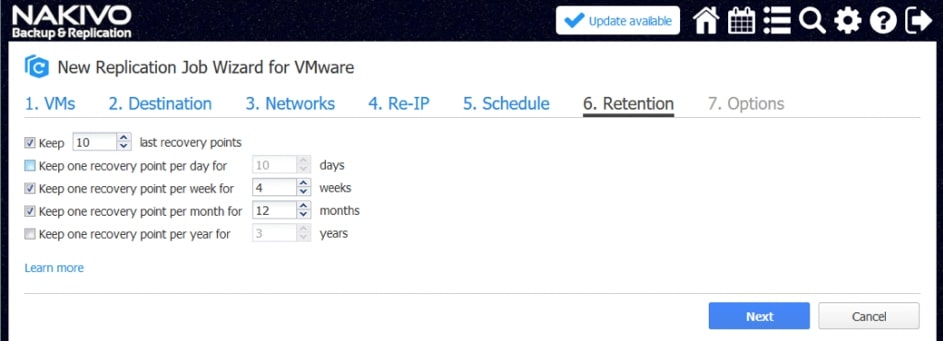
Punkty odzyskiwania
Punkt odzyskiwania reprezentuje maszynę wirtualną w określonym momencie, która następnie jest używana do odzyskiwania VM. Za pomocą narzędzia NAKIVO Backup & Replication można przechowywać do 30 punktów odzyskiwania na replikę maszyny wirtualnej. Produkt umożliwia zapisywanie punktów przywracania zgodnie z zasadami przechowywania Grandfather-Father-Son (GFS), jak opisano poniżej. Ta metoda zapewnia, że punkty odzyskiwania repliki VM są zapisywane w witrynie DR z wyznaczonymi częstotliwościami (np. codziennie, co tydzień, co miesiąc i co rok).
- Zachowaj jeden punkt przywracania na tydzień przez X tygodni: Ostatni punkt odzyskiwania każdego tygodnia jest przechowywany przez określoną liczbę tygodni.
- Zachowaj jeden punkt odzyskiwania miesięcznie przez X miesięcy: Ostatni punkt odzyskiwania każdego miesiąca jest przechowywany przez określoną liczbę miesięcy.
- Zachowaj jeden punkt odzyskiwania rocznie przez X lat: Ostatni punkt odzyskiwania każdego roku jest przechowywany przez określoną liczbę lat.
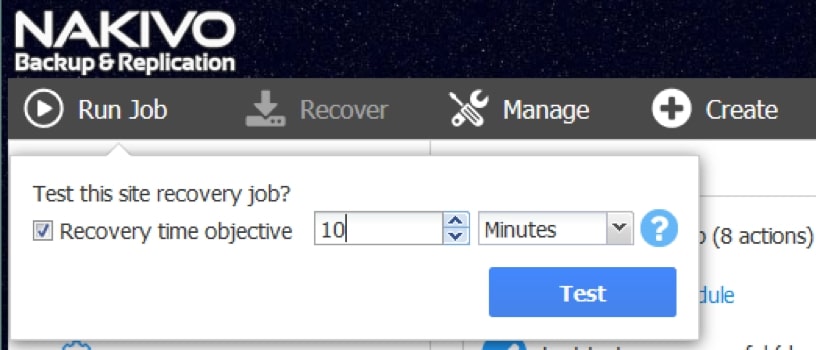
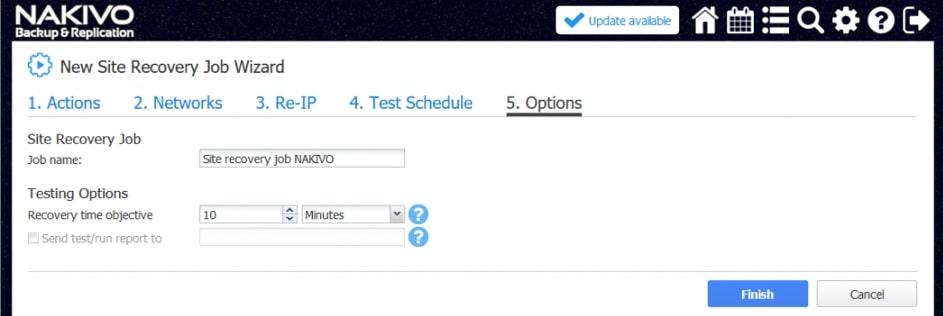
- RTO i RPO
Cel punktu odzyskiwania (RPO) to limit najwcześniejszego momentu, w którym maszyna wirtualna powinna zostać przywrócona podczas DR. W ten sposób określa ilość danych, które można utracić, nie powodując nieuzasadnionych szkód dla Twojej firmy. Replikacja może pomóc w spełnieniu krótszych RPO, ponieważ zadania replikacji można uruchamiać według potrzeb za pomocą niestandardowych harmonogramów ustawionych dla nich.
Replikacja maszyn wirtualnych może również pomóc w osiągnięciu krótkich czasów odzyskiwania (RTO). RTO to określony czas, w którym operacje biznesowe muszą zostać odzyskane po katastrofie. Dzięki replikacji maszynę wirtualną można natychmiast przywrócić, uruchamiając replikę.
Przypadki zastosowań
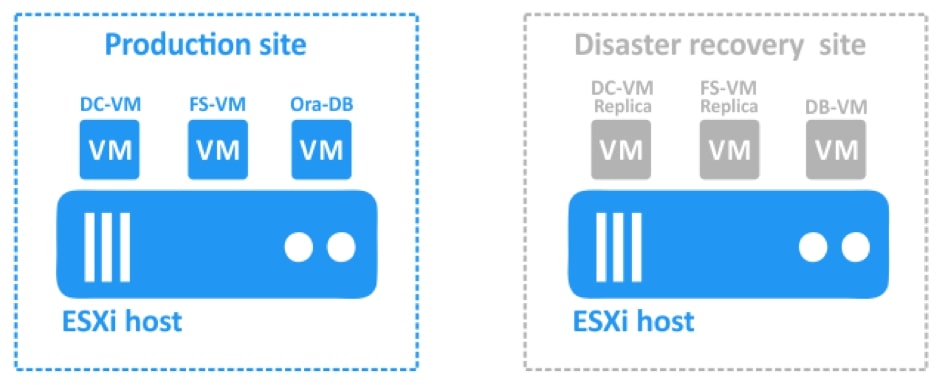
Replikacja maszyn wirtualnych może chronić usługi o kluczowym znaczeniu dla biznesu przed wieloma problemami, w tym powodowanymi przez krytyczną utratę VM/awarię maszyny wirtualnej, awarię hosta/magazynu danych lub klęski żywiołowe. Replikacja maszyn wirtualnych jest zwykle używana, gdy projekty działają z danymi wrażliwymi i/lub tolerują utratę danych zerowych. Replikacja jest odpowiednia dla tych przypadków, ponieważ odzyskiwanie VM może być wykonane łatwo i prawie natychmiast po wystąpieniu awarii.
Funkcja replikacji jest używana w następujących przypadkach:
- Odzyskiwanie po awarii z repliką
Za pomocą NAKIVO Backup & Replication można w znacznym stopniu złagodzić negatywne skutki awarii systemu, takie jak przestoje i utrata dochodów. Dzięki replikacji maszyn wirtualnych możesz niemal natychmiast odzyskać całą maszynę wirtualną za pomocą jej repliki, zapewniając w ten sposób wysoką dostępność usług biznesowych.
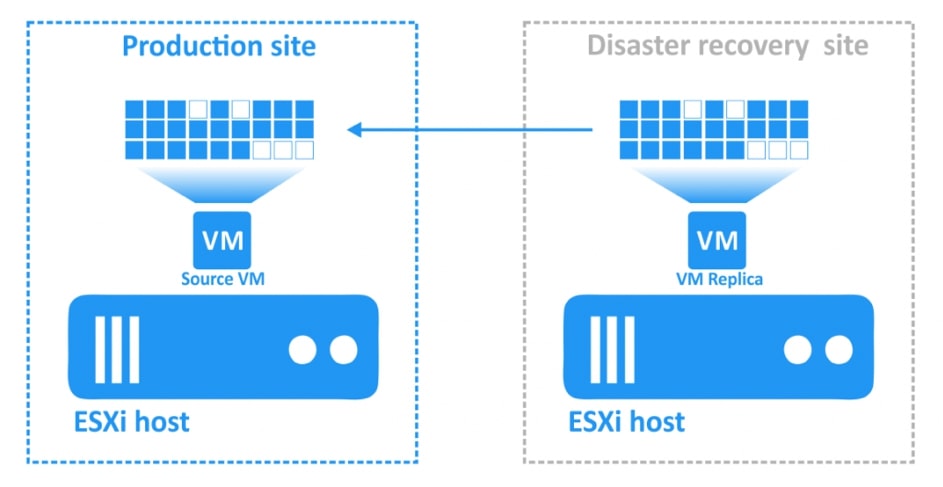
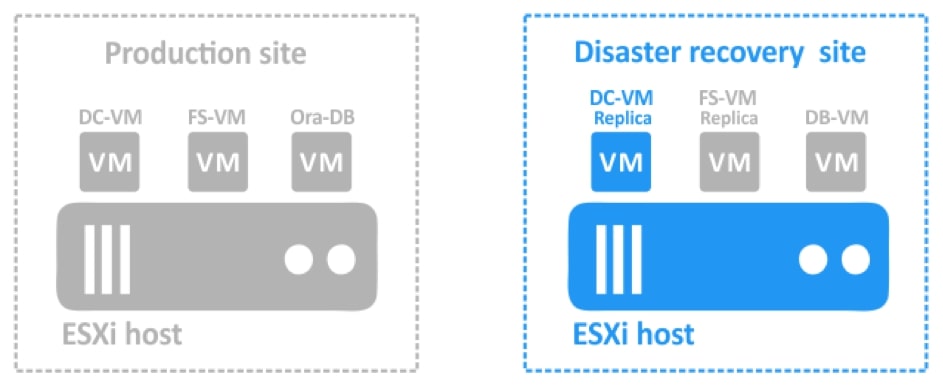
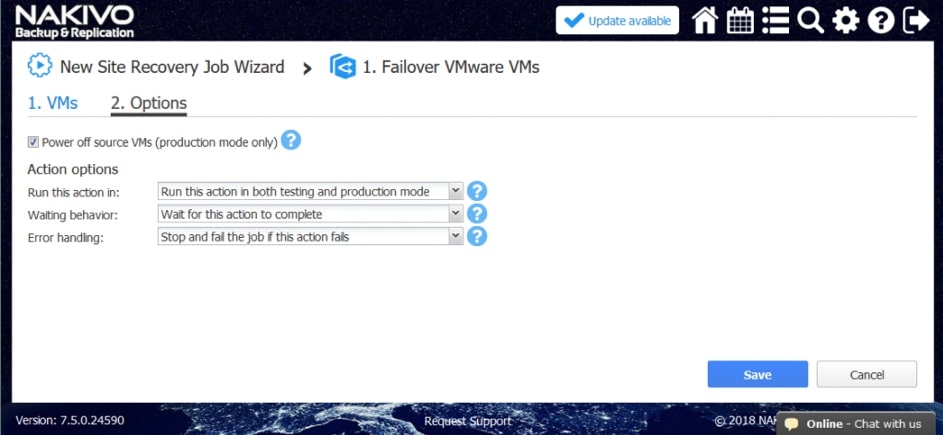
- Przełączanie awaryjne oraz powrót po awarii
Kiedy katastrofa pozbawi nas podstawowej bazy danych, firma może zostać poważnie dotknięta – chyba że mamy efektywny plan DR. Tutaj przydatne jest przełączanie awaryjne. Przełączanie awaryjne, to proces przełączania ze źródłowej maszyny wirtualnej na replikę maszyny wirtualnej w celu przeniesienia obciążeń o znaczeniu krytycznym z witryny, której dotyczy problem, do witryny DR.
Po przywróceniu głównej lokacji możesz przełączyć operacje biznesowe z powrotem na oryginalną maszynę wirtualną. Ten proces nazywany jest funkcją powrotu po awarii i umożliwia synchronizację danych między lokacją główną a witryną DR.
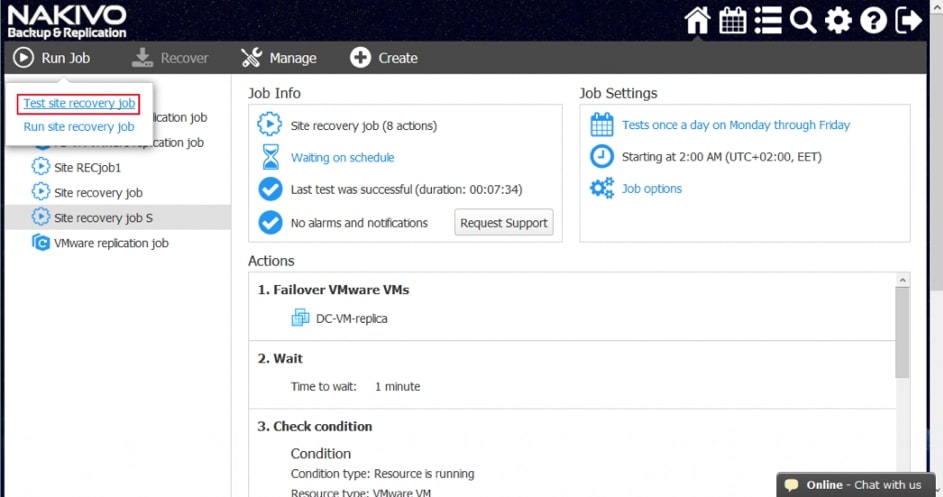
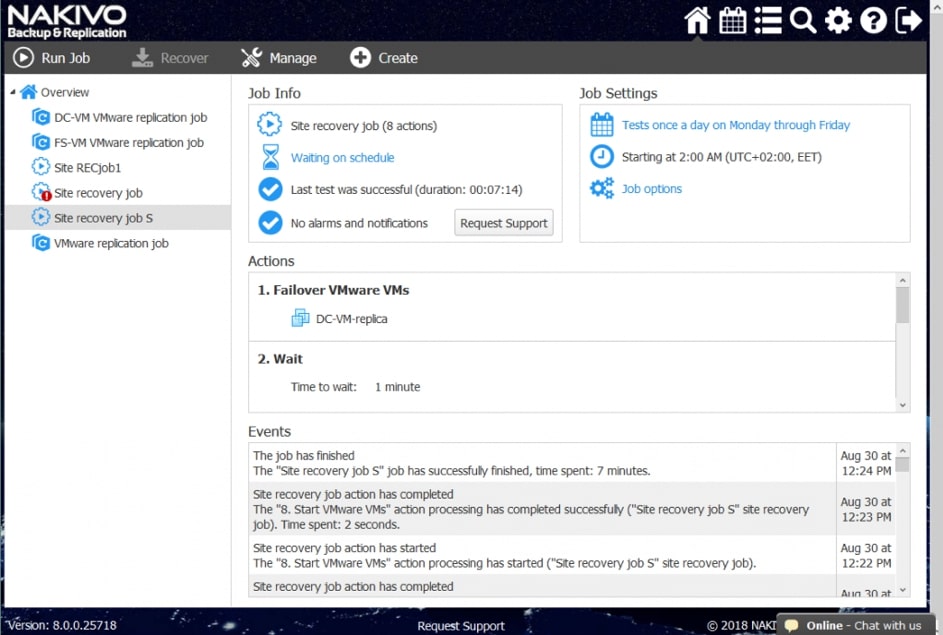
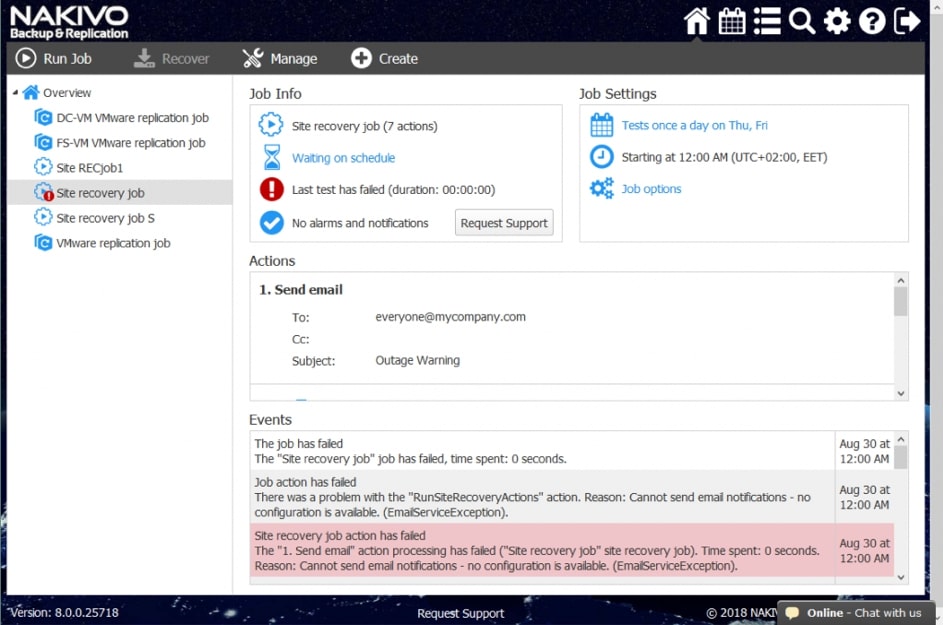
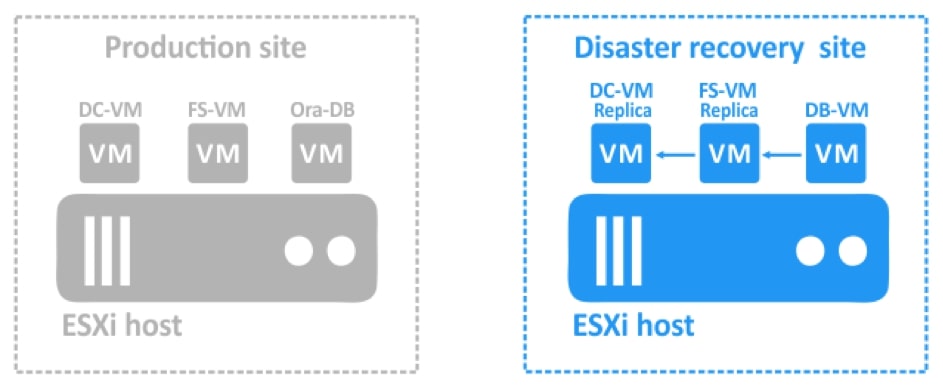
- Odzyskiwanie lokalizacji
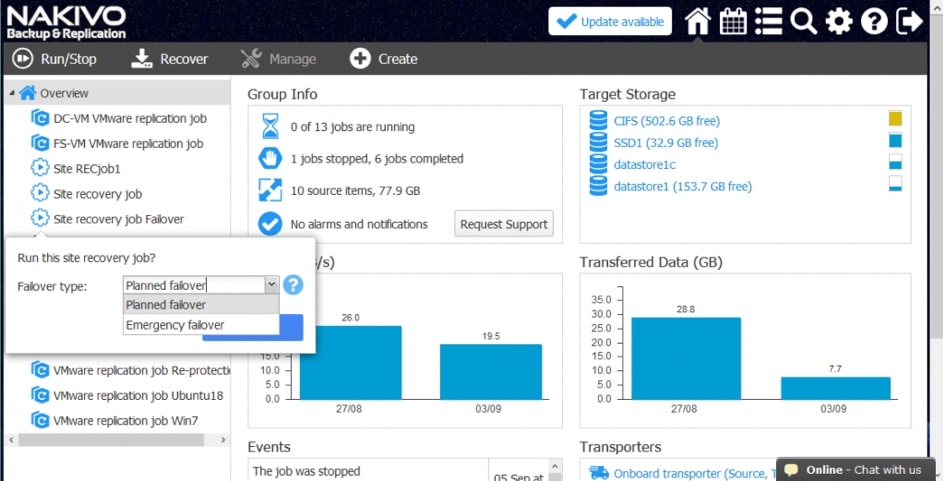
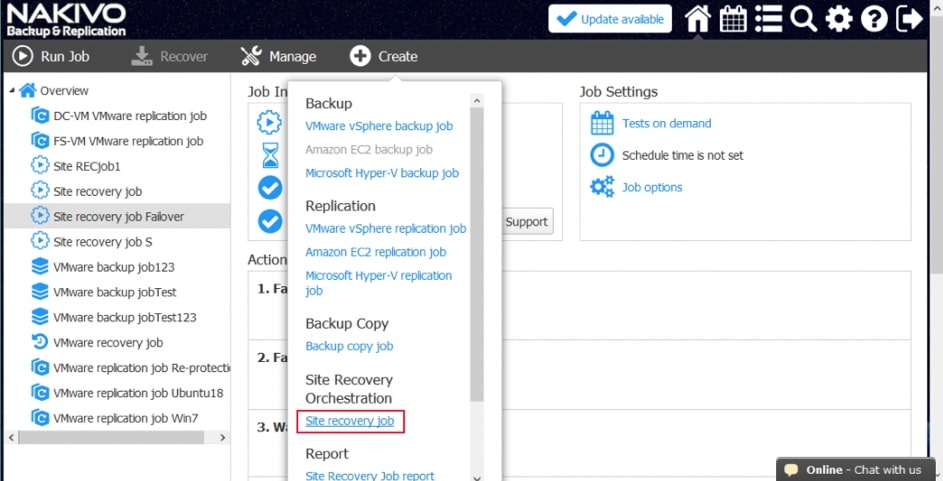
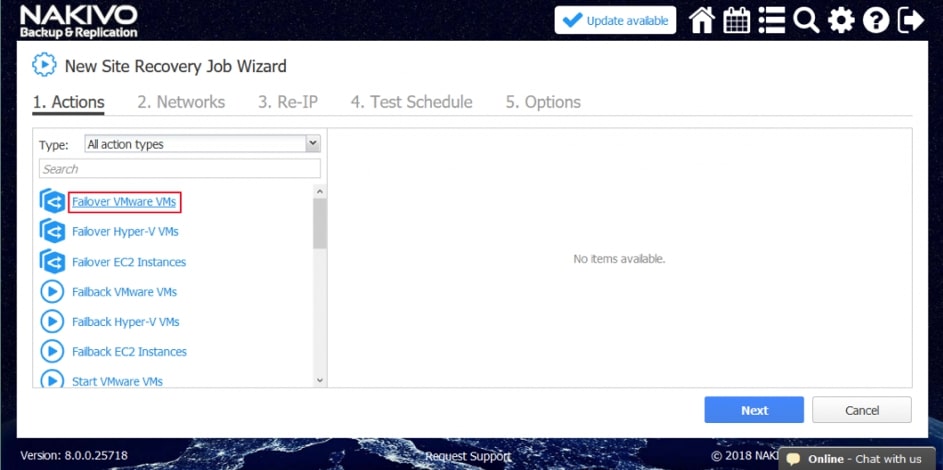
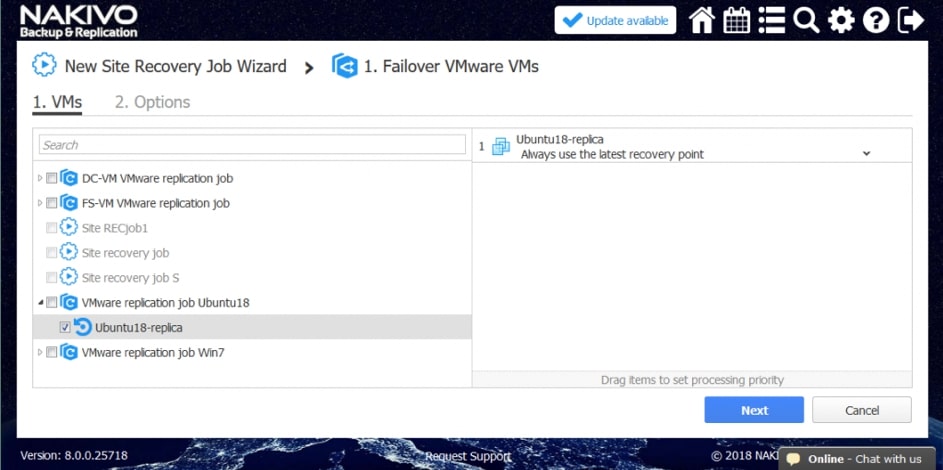
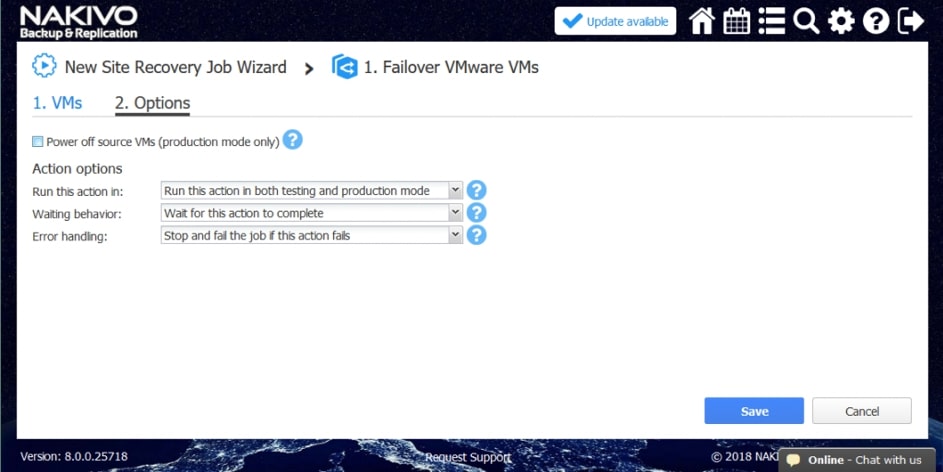
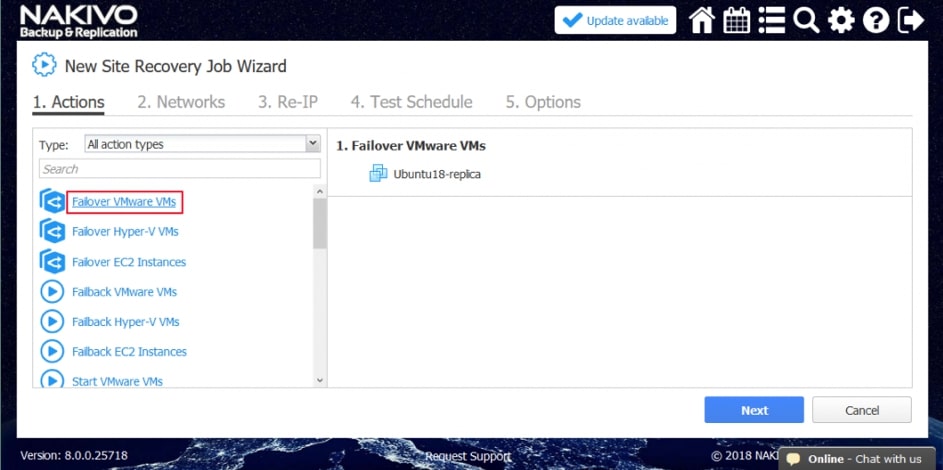
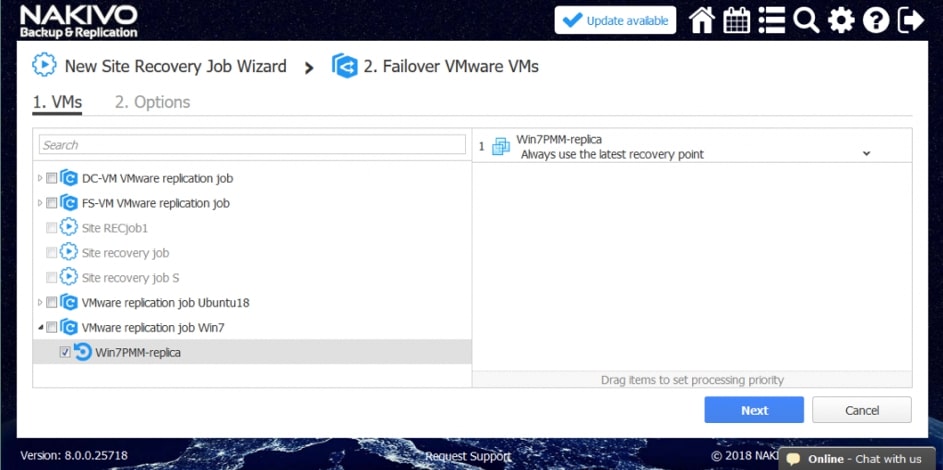
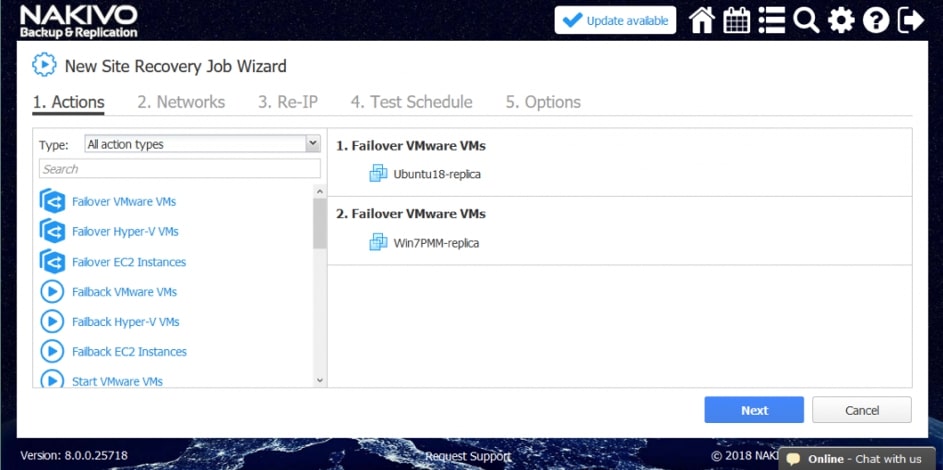
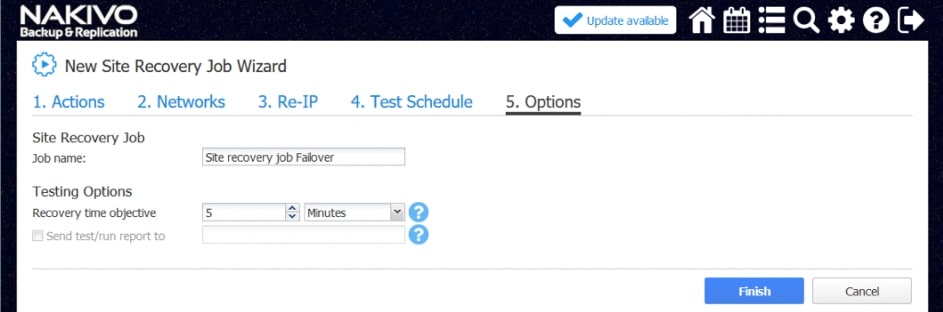
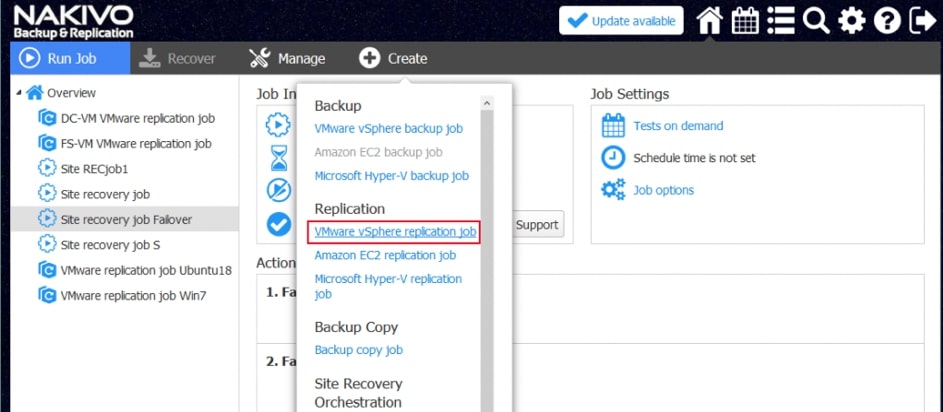
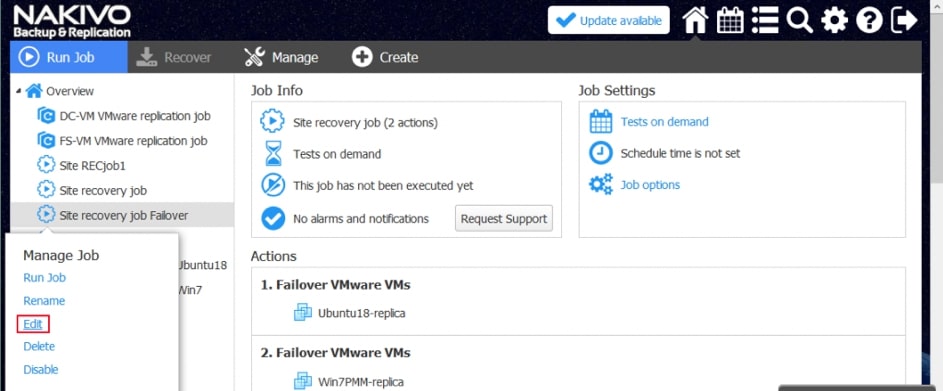
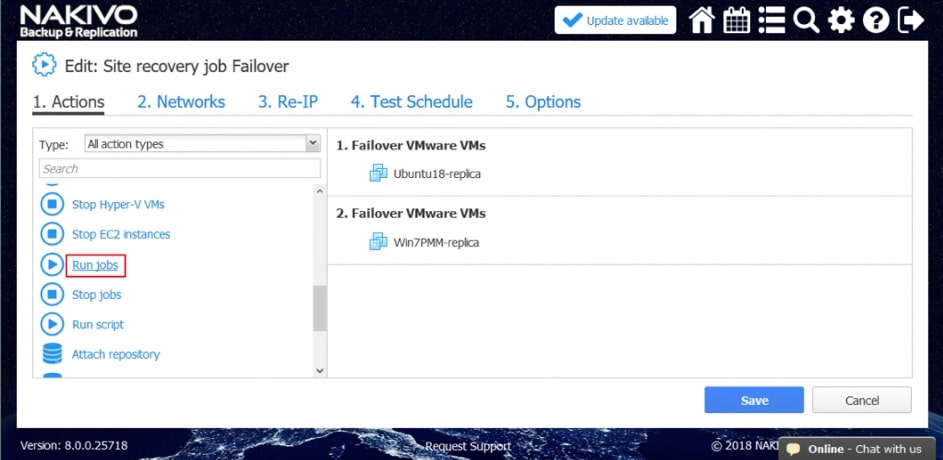
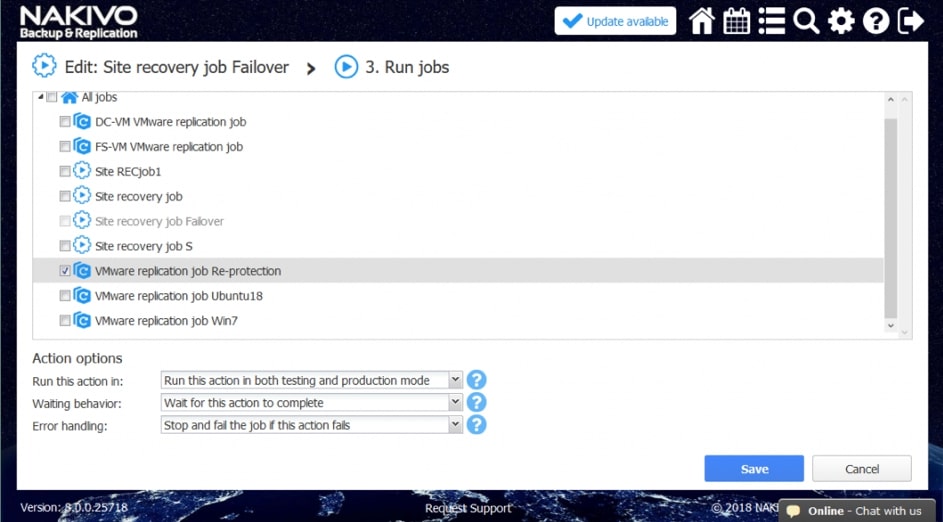
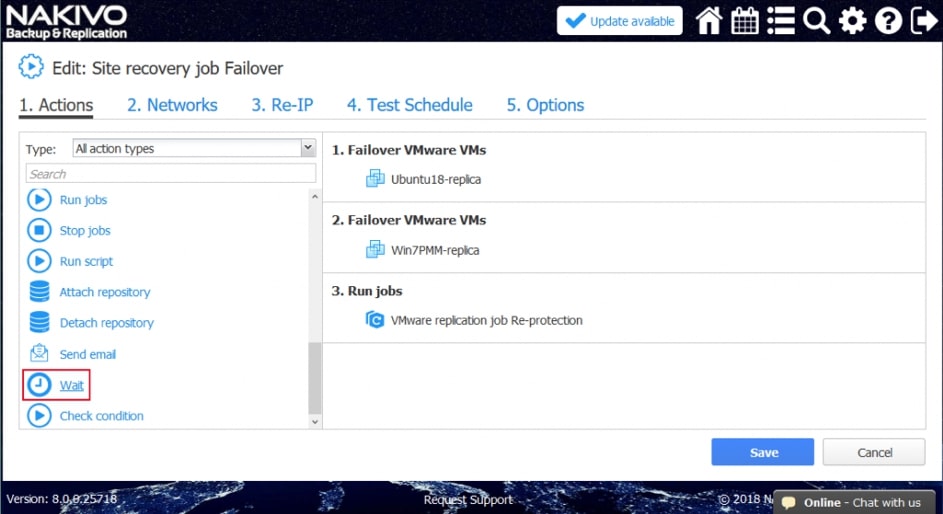
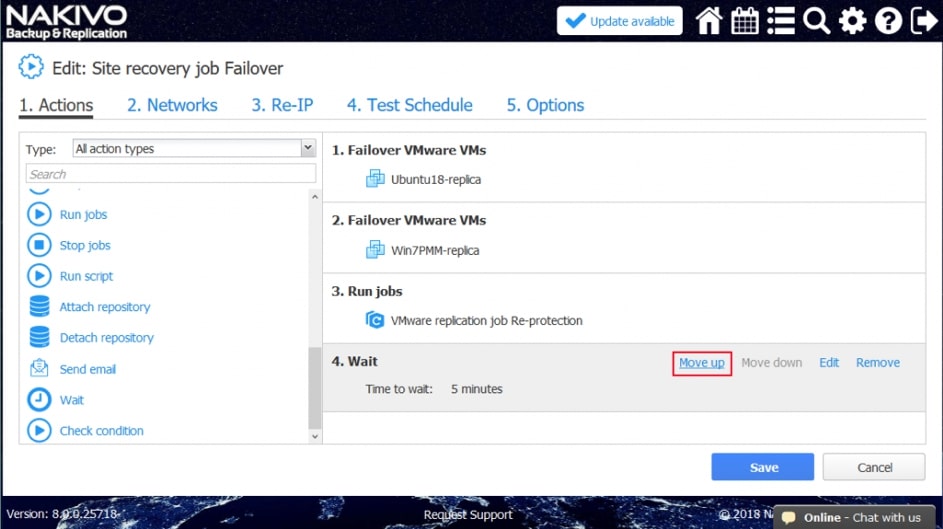
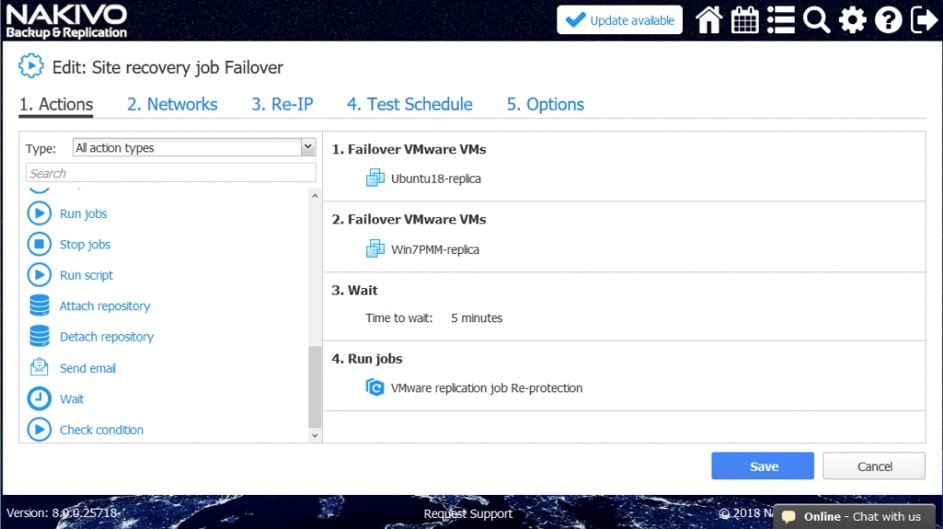
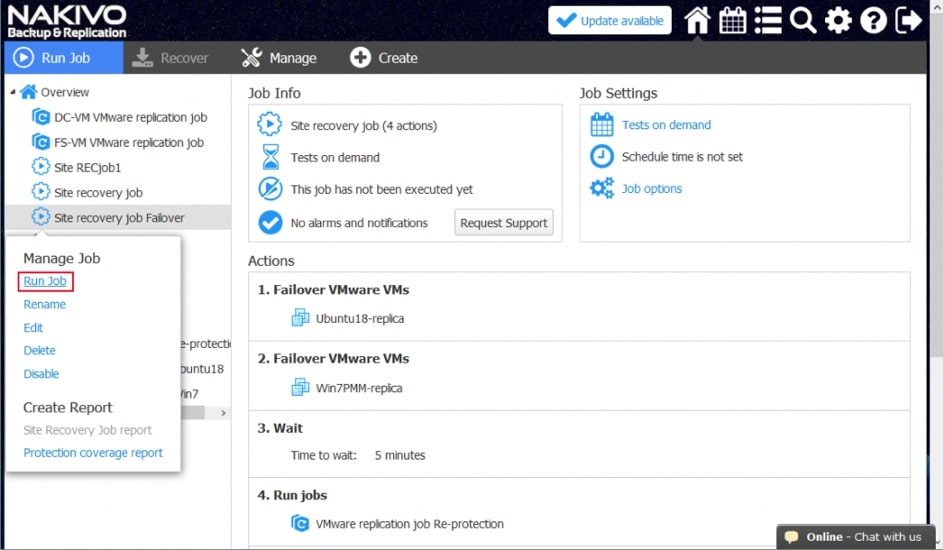
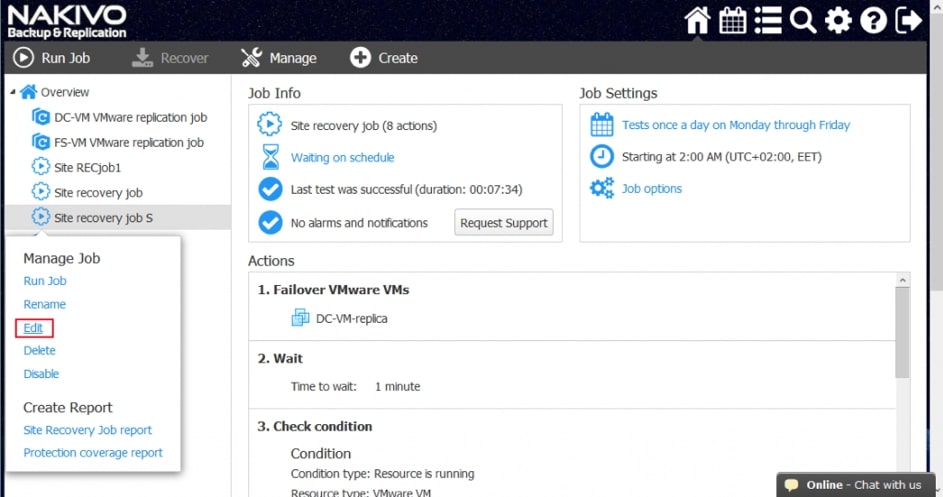
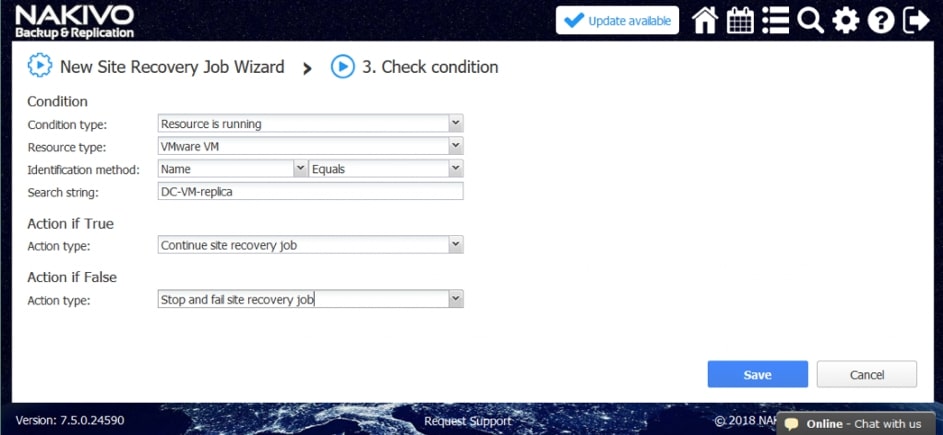
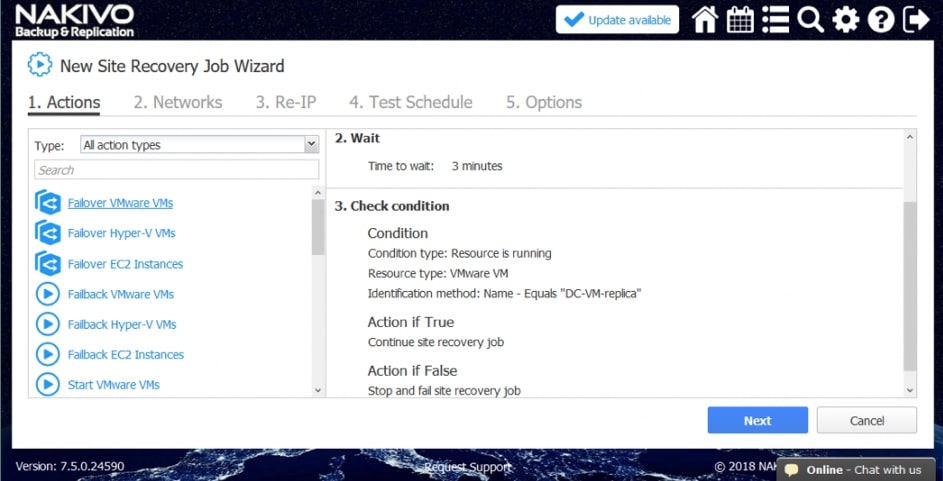
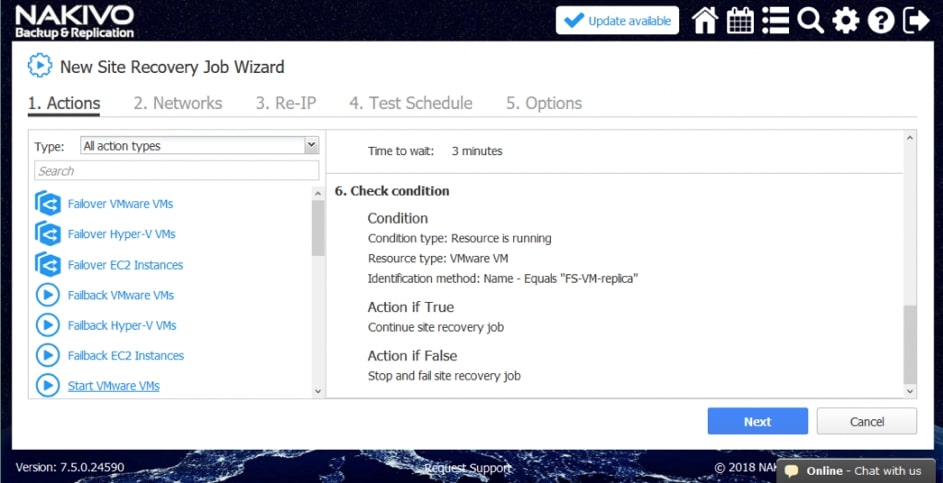
Za pomocą narzędzia NAKIVO Backup & Replication można tworzyć przepływy pracy (zadania) odzyskiwania lokalizacji, które są łatwymi w konfiguracji niestandardowymi algorytmami do automatyzacji i orkiestracji procesu DR. Ręczna realizacja planu odzyskiwania po awarii może być czasochłonnym i wymagającym dużej ilości zasobów zadaniem. Na szczęście, NAKIVO Backup & Replication pozwala organizować akcje w zadania odzyskiwania lokalizacji, które można uruchomić za pomocą zaledwie kilku kliknięć. Możesz utworzyć specjalne zadania Site Recovery, aby poradzić sobie z dowolnym zdarzeniem DR.
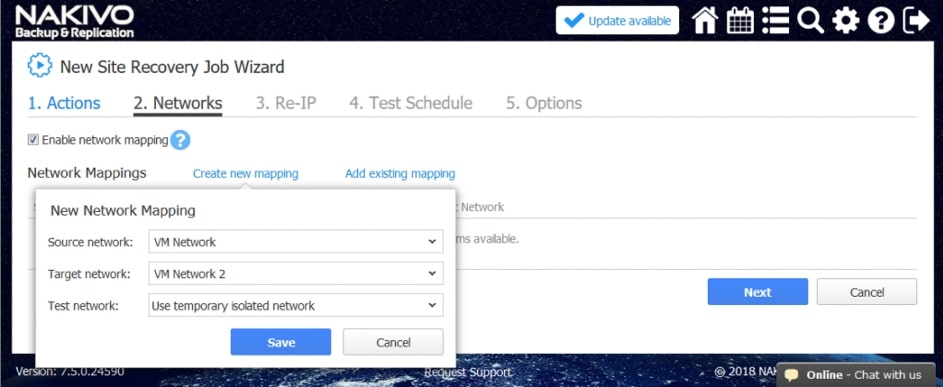
Poniższe działania i warunki można uwzględnić w przepływach pracy odzyskiwania lokalizacji:
- Przełączanie awaryjne maszyn wirtualnych. Przejście do już utworzonej repliki VM.
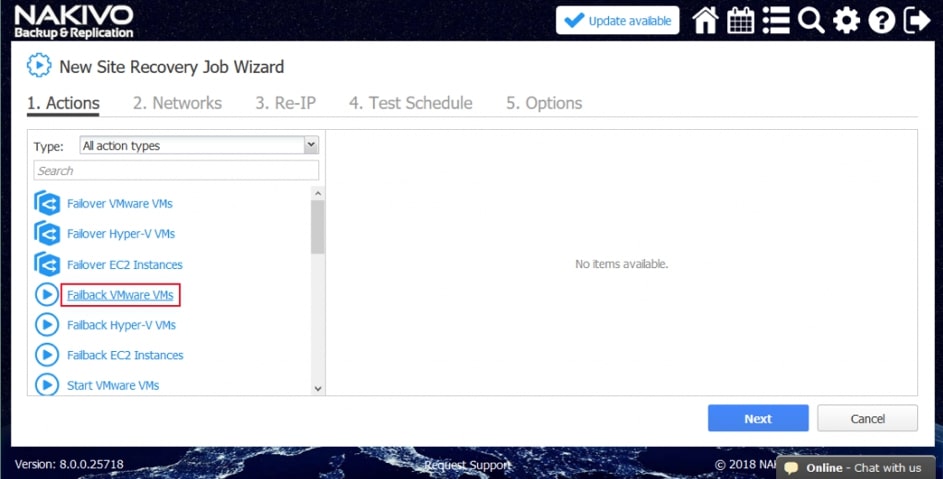
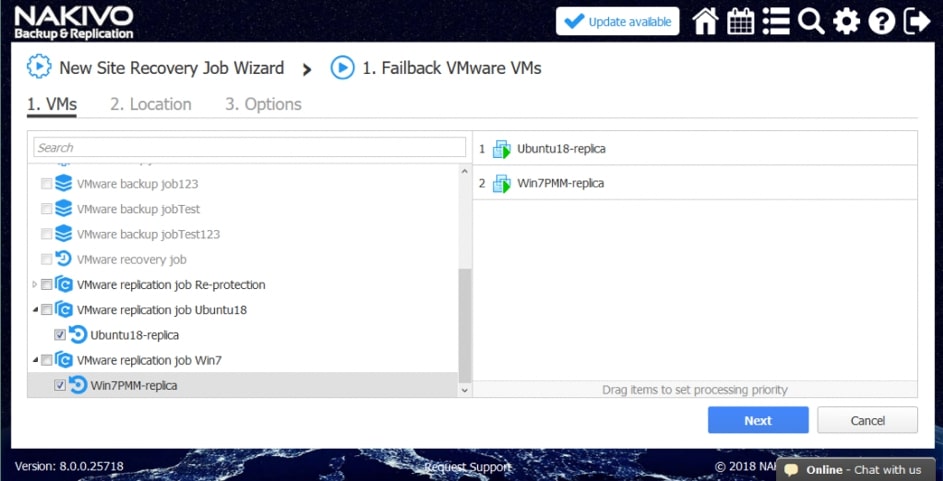
- Powrót po awarii maszyn wirtualnych. Przeniesienie obciążeń z powrotem z repliki maszyny wirtualnej w witrynie DR do źródłowej maszyny wirtualnej w miejscu produkcji.
- Uruchomienie maszyn wirtualnych. Uruchamiamy jedną lub wiele maszyn wirtualnych.
- Zatrzymanie maszyn wirtualnych. Zatrzymanie jednej lub wielu maszyn wirtualnych.
- Uruchomienie zadań. Uruchomienie zadań ochrony danych (tworzenie kopii zapasowych, replikacja itd.), które już zostały utworzone dla maszyn wirtualnych.
- Zatrzymanie zadań. Zatrzymanie zadań ochrony danych VM, które są uruchomione.
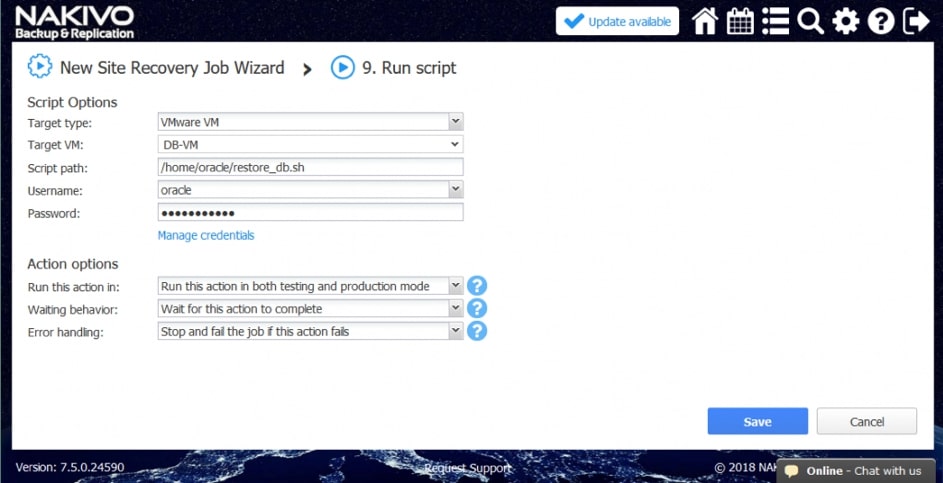
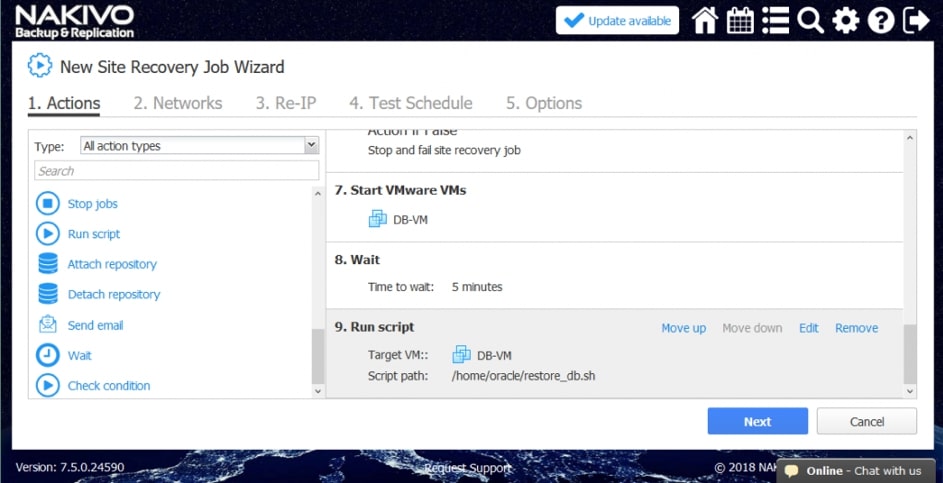
- Uruchomienie skryptu. Uruchomienie własnego skryptu przed lub po zadaniu na komputerze z systemem Windows lub Linux.
- Załączenie repozytorium. Dołączenie repozytorium kopii zapasowych.
- Odłączenie repozytorium. Odłączenie dołączonych repozytorium kopii zapasowych.
- Wysyłanie e-maili. Otrzymywanie powiadomień e-mail z informacją o wynikach po wykonaniu określonej czynności.
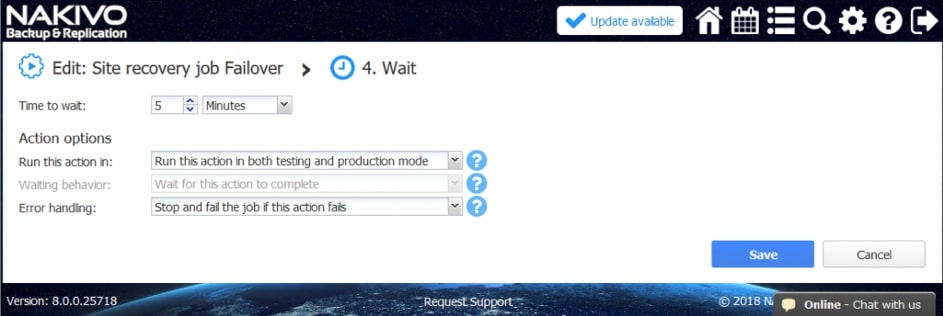
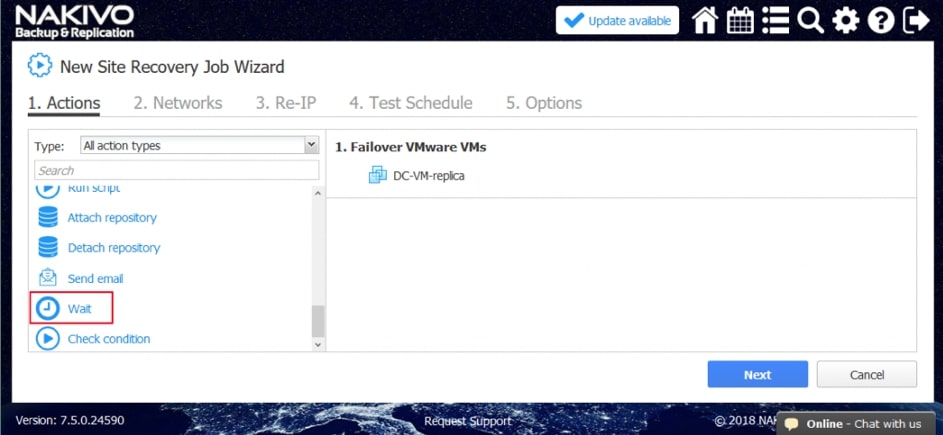
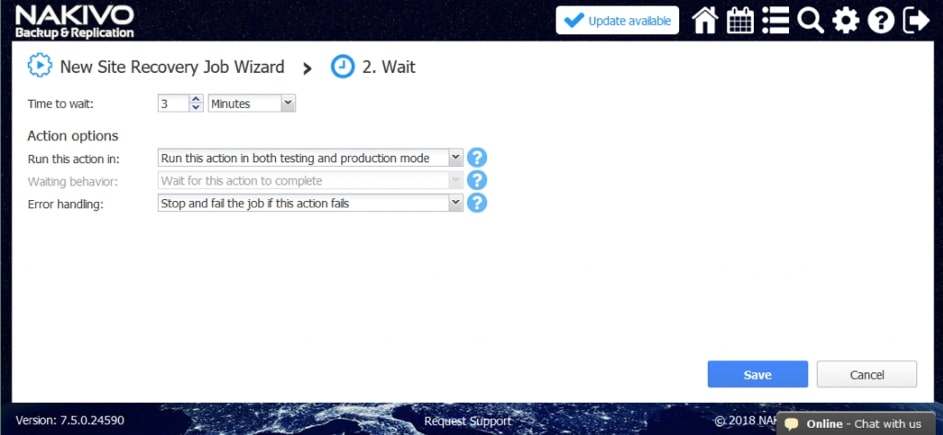
- Czekać. Zaczekaj na określony czas przed rozpoczęciem następnej akcji.
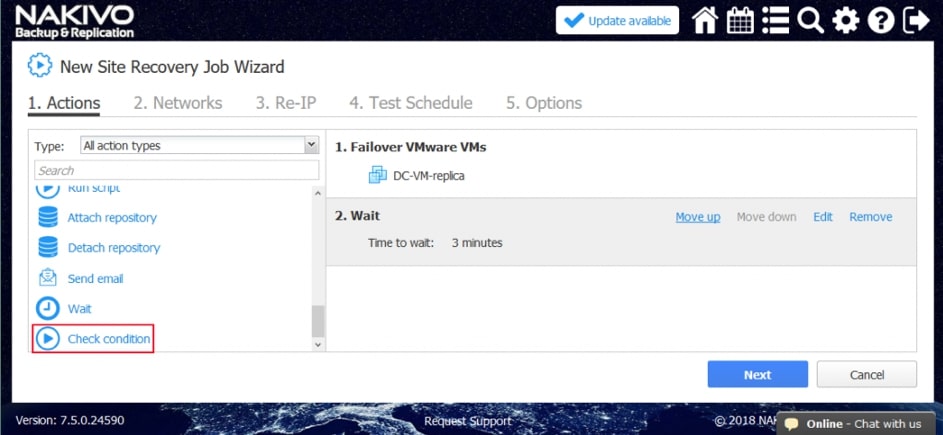
- Sprawdź stan. Sprawdź, czy istnieje zasób, czy uruchomiony jest zasób, lub czy adres IP/nazwa hosta są osiągalne przed przejściem do następnej czynności.
Wnioski
Każda firma może paść ofiarą niespodziewanej katastrofy lub awarii systemu, która może zagrozić integralności ważnych dla firmy danych. To sprawia, że posiadanie efektywnego planu DR jest absolutnie niezbędne w nowoczesnym świecie biznesu, gdzie wysoka dostępność i ciągłość biznesowa są najważniejsze.
Replikacja może stać się nieocenionym narzędziem dla DR. Synchroniczne i asynchroniczne strategie replikacji powinny być wdrażane inteligentnie, w zależności od priorytetów i potrzeb biznesowych. Asynchroniczna replikacja to opłacalna strategia, która wymaga mniejszej przepustowości i braku dodatkowego sprzętu. Może być używany do przechowywania mniej wrażliwych danych i przesyłania danych na duże odległości. Chociaż replikacja synchroniczna jest wysoce zależna od połączenia sieciowego i opóźnień, gwarantuje zerową utratę danych i pozwala natychmiastowo przywrócić operacje o znaczeniu krytycznym.
NAKIVO Backup & Replication to szybkie i elastyczne rozwiązanie, które może replikować maszyny wirtualne do jednej lub więcej zdalnych lokalizacji w celu niezawodnego przechowywania. Dzięki rozwiązaniu można po prostu włączyć repliki podczas awarii, unikając w ten sposób utraty przychodów i długotrwałego wyłączania.