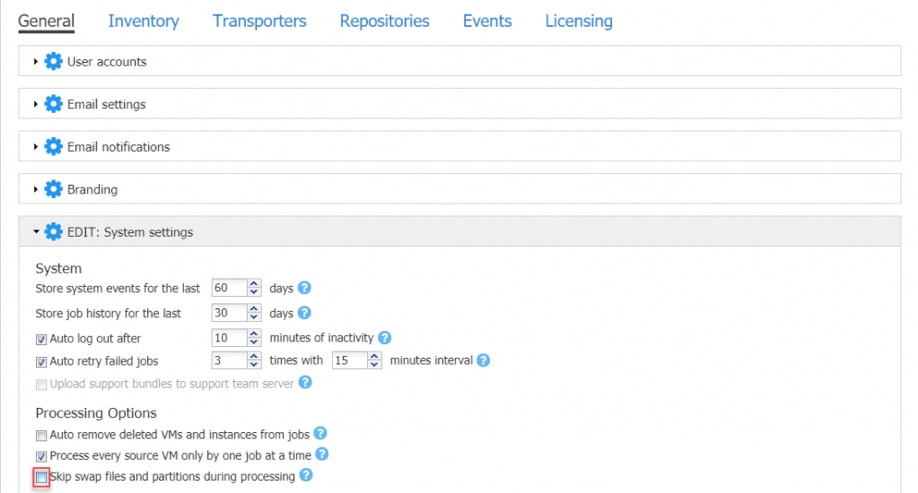
Miło nam poinformować, że pojawiła się nowa wersja NAKIVO Backup & Replication 8.0. Tym samym Nakivo weszło na rynek rozwiązań do odzyskiwaniae danych po awarii dla przedsiębiorstw. Najnowsza wersja zawiera zaawansowaną funkcję Site Recovery, która jest potężnym narzędziem do odzyskiwania danych dla środowisk VMware, Hyper-V i AWS EC2. Funkcja ta umożliwia tworzenie zautomatyzowanych przepływów procesów odzyskiwania, testowanie ich w sposób niezakłócony i wykonanie przełączania awaryjnego za pomocą jednego kliknięcia – wszystko w jednym wygodnym interfejsie webowym. Będzie ona jeszcze dokładnie przez nas badana i zapewne pojawi się w kolejnych artykułach na blogu.
Przedstawiamy Site Recovery przez NAKIVO
Narzędzie Site Recovery zostało zaprojektowane w celu aranżowania i automatyzowania procesu odzyskiwania danych po awarii maszyny wirtualnej. Funkcja pozwala tworzyć niestandardowe przepływy pracy odzyskiwania (tj. zadania Site Recovery) z zestawu dostępnych działań, w tym:
- Failover – Przełączanie awaryjne maszyn wirtualnych VMware, maszyn wirtualnych Hyper-V i AWS EC2 (można awaryjnie przejść do poprzednio utworzonej repliki)
- Failback – Powrót awaryjny maszyn wirtualnych VMware, maszyn wirtualnych Hyper-V i AWS EC2 (można przenieść obciążenia z powrotem z repliki w witrynie DR do źródłowej maszyny wirtualnej lub instancji po ponownym użyciu głównej lokacji)
- Start – Uruchom instancje VMware VM, Hyper-V VM lub AWS EC2
- Stop – Zatrzymaj instancje VMware VM, Hyper-V VM lub AWS EC2
- Run jobs – Uruchom zadania (możesz uruchomić wszystkie utworzone zadania)
- Stop jobs – Zatrzymaj zadania (możesz zatrzymać zadanie, które już działa)
- Run script – Uruchom skrypt (możesz wykonać dowolny skrypt na komputerach z systemem Linux lub Windows)
- Attach repository – Dołącz repozytorium (możesz dołączyć repozytorium kopii zapasowych)
- Detach repository – Odłącz repozytorium (możesz odłączyć repozytorium, które jest już dołączone)
- Send e-mail – Wyślij e-mail (możesz wysłać wiadomość e-mail powiadamiając zainteresowane strony, jeśli akcja zakończy się pomyślnie lub się nie powiedzie)
- Wait – Poczekaj (możesz odczekać określony czas, zanim przejdziesz do następnej akcji w przepływie pracy zadania)
- Check condition – Sprawdź stan. Przed rozpoczęciem odpowiedniego postępowania można sprawdzić dowolny z następujących warunków:
- czy istnieje konkretna maszyna wirtualna/wystąpienie
- czy konkretna maszyna wirtualna/instancja działa
- czy host jest osiągalny
Akcje można uruchamiać w dowolnej kolejności, która odpowiada aktualnym potrzebom i procedurom odzyskiwania.
Tryb testowy i tryb produkcji
Zadanie Site Recovery można uruchomić w trybie testowym lub w trybie produkcyjnym. Głównym celem trybu testowego jest sprawdzenie, czy maszyny wirtualne można odzyskać zgodnie z planem odzyskiwania po awarii w ramach docelowych ram czasowych (RTO). Podczas wykonywania zadania przywracania lokacji w trybie testowym akcje takie jak Start/Stop VM, Failover/Failback i Attach/Detach Repository są przywracane po zakończeniu testu.
Spowoduje to powrót środowiska do stanu początkowego, dzięki czemu będzie ono gotowe do uruchomienia zadania w trybie produkcji, gdy będzie to konieczne. Gdy zadanie przywracania lokacji uruchamiane jest w trybie produkcyjnym, środowisko wirtualne jest odzyskiwane (np. po awarii), a działania nie są odwracane po zakończeniu zadania. Źródłowa maszyna wirtualna może zostać wyłączona, a zadania zmigrowane do replik VM w witrynie DR.
Kroki odzyskiwania witryny
Cały proces odzyskiwania przeprowadzany za pomocą funkcji Site Recovery powinien składać się z kilku kroków, w tym replikacji maszyn wirtualnych, tworzenia przepływu pracy, testowania przepływu pracy, uruchamiania przełączania awaryjnego, a następnie przywracania do poprzedniego stanu (tj. uruchamiania po awarii). Konkretne podejście będzie jednak zależało od potrzeb klienta.
Konfigurowanie replikacji maszyny wirtualnej
Posiadanie repliki jest warunkiem wstępnym do działania w trybie failover w ramach Site Recovery. Oprogramowanie NAKIVO Backup&Replication może skutecznie replikować maszyny wirtualne lub instancje, korzystając z podejścia uwzględniającego aplikacje. Należy wybrać, które źródłowe maszyny wirtualne/instancje powinny zostać zreplikowane, a następnie zdefiniować serwer docelowy i magazyn danych dla replik.
Tworzenie procesu odzyskiwania
Aby utworzyć zadanie Site Recovery, trzeba po prostu skomponować poprawną sekwencję czynności, korzystając z opcji wymienionych powyżej. Na przykład można utworzyć następujący przepływ pracy:
- Przełączanie awaryjne VM1 do repliki w witrynie DR
- Sprawdź stan: Sprawdź, czy VM1 działa. Jeśli VM1 jest uruchomiona, przejdź do następnego kroku
- Poczekaj 5 minut
- Przełączanie awaryjne VM2. Dla celów tego przykładu załóżmy, że VM2 musi działać, aby VM1 działało poprawnie (np. VM1 uruchamia bazę danych SQL, od której zależy VM2)
- Sprawdź stan: Sprawdź, czy działa VM2. Jeśli VM2 działa, przejdź do następnego kroku
- Uruchom skrypt na VM2
- Wyślij wiadomość e-mail: poinformuj personel działu, że przełączenie awaryjne zostało pomyślnie wykonane
Jest to uproszczony przykład, który pozwala zorientować się, w jaki sposób podstawowy przepływ pracy awaryjnej DR VM będzie działał z NAKIVO Backup & Replication. Można tworzyć wiele zadań przywracania lokacji dla różnych sytuacji. Takie podejście sprawia, że odzyskiwanie danych po awarii jest bardziej elastyczne i pomaga szybciej odzyskiwać infrastrukturę wirtualną wraz z usługami, które na niej działają.
Przeprowadzanie testu pracy awaryjnej
Jak opisano powyżej, zadanie przywracania lokacji, które zawiera działania przełączania awaryjnego, może być uruchomione w trybie testowym. Najlepsze praktyki nakazują uruchamianie zadania Site Recovery w trybie testowym zaraz po jego utworzeniu.
W ten sposób mamy gwarancję, że wszystko będzie działać zgodnie z planem i będzie to można odzyskać pomyślnie w odpowiednim czasie. Można zaplanować zadanie przywracania lokacji, aby okresowo działało w trybie testowym. Aby uruchomić zadanie przywracania lokacji w trybie produkcyjnym, należy ręcznie zainicjować zadanie.
Uruchomienie pracy awaryjnej
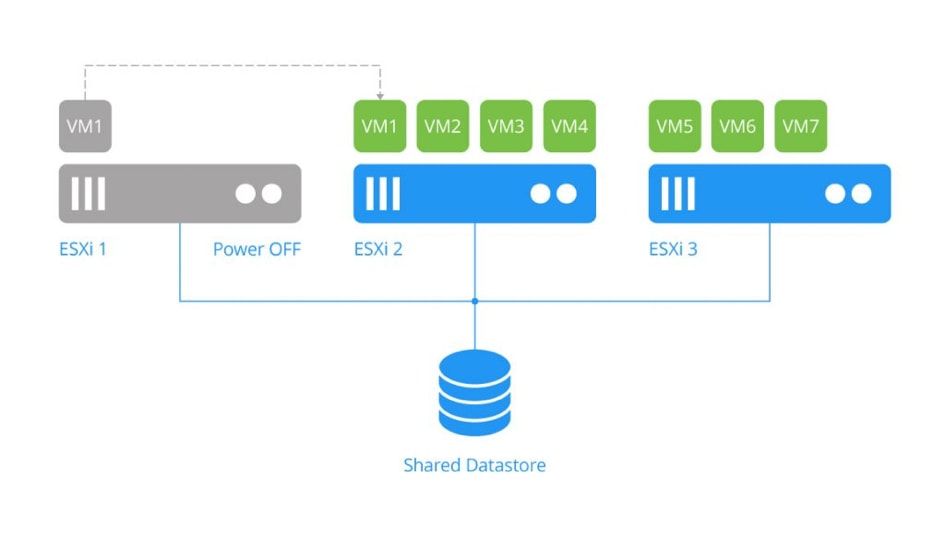
Przełączanie awaryjne, to proces przełączania z uszkodzonej maszyny wirtualnej w miejscu produkcji na replikę maszyny wirtualnej w witrynie DR. Przełączanie awaryjne jest jedną z czynności dostępnych dla zadania Site Recovery. Źródłowa maszyna wirtualna VM może być elastycznie wyłączana podczas pracy awaryjnej dzięki funkcji odzyskiwania witryny NAKIVO Backup & Replication.
Opcja VM Power off source może być przydatna, gdy źródłowa maszyna wirtualna jest nadal włączona, ale działa nieprawidłowo po awarii.
Wykonywanie powrotu po awarii
Powrót awaryjny, to proces przywracania obciążeń do źródłowej maszyny wirtualnej za pomocą repliki VM, która została użyta do odzyskiwania po awarii. Proces powrotu po awarii jest zasadniczo odwrotnością procesu przełączania awaryjnego. Po przełączeniu awaryjnym do repliki wszystkie zmiany są zapisywane w replice na stronie DR.
Po odzyskaniu witryny produkcyjnej należy przenieść tam obciążenia. Źródłowa maszyna wirtualna musi zostać zsynchronizowana z jej repliką maszyny wirtualnej, aby zaktualizować stan maszyny wirtualnej, ponieważ nowe dane (od momentu przełączenia awaryjnego) zostały zapisane tylko w replice maszyny wirtualnej. Operacja powrotu po awarii replikuje dane z repliki maszyny wirtualnej z powrotem do źródłowej maszyny wirtualnej.
Zalety przywracania witryny jako narzędzia do odzyskiwania po awarii
Kompleksowa orkiestracja i automatyzacja DR. Site Recovery pozwala wdrażać plany odzyskiwania po awarii przy wysokim poziomie automatyzacji. Można zdefiniować kolejność odzyskiwania VM z uwzględnieniem zależności VM, tak aby po wystąpieniu awarii odzyskiwanie było tak wydajne, jak to tylko możliwe.
Elastyczność w celu dostosowania do potrzeb różnych firm. Mona utworzyć wiele zadań przywracania witryny w zależności od potrzeb. Zestaw dostępnych akcji do włączenia w Site Recovery umożliwia tworzenie różnych przepływów pracy odzyskiwania dostosowanych do różnych sytuacji.
Wbudowany w rozwiązanie do ochrony danych. Site Recovery, to funkcja zawarta w oprogramowaniu NAKIVO Backup & Replication i dostępna wraz z pozostałą częścią kompleksowego zestawu funkcji produktu; nie musisz kupować oddzielnej licencji. Dzięki temu rozwiązaniu wszystkie czynności związane z ochroną danych i odzyskiwaniem danych po awarii są zarządzane z jednej konsoli.
Znaczne oszczędności w porównaniu do innych rozwiązań DR. Program NAKIVO Backup & Replication z wbudowanym narzędziem Site Recovery, to ekonomiczne rozwiązanie. Produkt nadal oferuje użytkownikom przydatne nowe funkcje przy zachowaniu tych samych przystępnych cen – zwłaszcza w porównaniu z konkurencją.