QNAP, wiodący dostawca rozwiązań z dziedziny storage, network oraz computing udostępnił dziś wydanie 4.4.1 Beta systemu operacyjnego QTS. Podczas prac nad nową wersją OS-u nacisk położono m.in. na wysoko wydajny backup oraz innowacyjny storage hybrydowy – dlatego QTS 4.4.1 wyposażono w aplikację HBS 3 z technologią QuDedup, która deduplikuje dane u źródła i zwiększa wydajność tworzenia backupu oraz przywracania danych. Wśród nowości jest również CacheMount (rozwiązanie pozwalające na lokalne cache’owanie danych z podłączonych usług chmurowych – co pozwala na korzystanie z nich również wygodnie jak w przypadku zasobów dostępnych w LAN) oraz QuMagie – bazująca na sztucznej inteligencji (AI) aplikacja do organizowania zdjęć i udostępniania ich. QNAP NAS z nowym systemem obsługiwać będzie również Fibre Channel SAN, co pozwoli na łatwe podłączenie urządzenia do istniejącego środowiska SAN i wykorzystanie go w charakterze atrakcyjnego kosztowo rozwiązania storage i backup.
“QTS 4.4.1 integruje Linux Kernel 4.14 LTS i obsługuje platformy sprzętowe następnej generacji, dzięki czemu urządzenia QNAP NAS będą mogły w pełni wykorzystać potencjał najnowszych rozwiązań technologicznych. W odpowiedzi na rosnącą popularność chmury hybrydowej w QTS 4.4.1 zoptymalizowaliśmy wydajność backupu i wprowadziliśmy innowacyjne aplikacje skrojone pod specyfikę środowisk hybrydowych – dzięki czemu użytkownicy domowi i biznesowi mogą korzystać z elastycznego alokowania przestrzeni dyskowej, wygodnie nią zarządzać i efektywnie tworzyć backup oraz przywracać dane. Priorytetem QNAP jest integrowanie w naszych produktach najnowocześniejszych technologii i zapewnianie użytkownikom najpełniejszego zestawu funkcji i narzędzi” – wyjaśnia Ken Cheah, Product Manager QNAP.
Więcej informacji o QTS 4.4.1: https://www.qnap.com/go/qts/4.4.1
Kluczowe nowe aplikacje i funkcje w QTS 4.4.1:
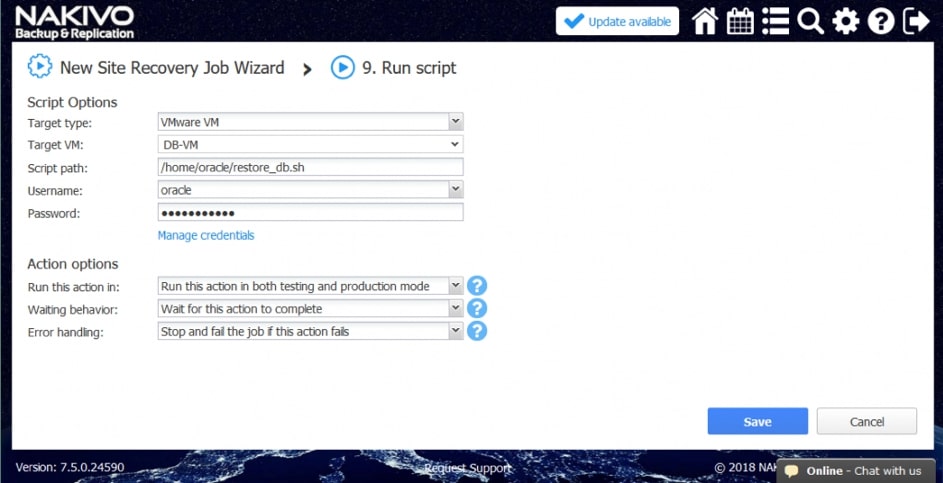
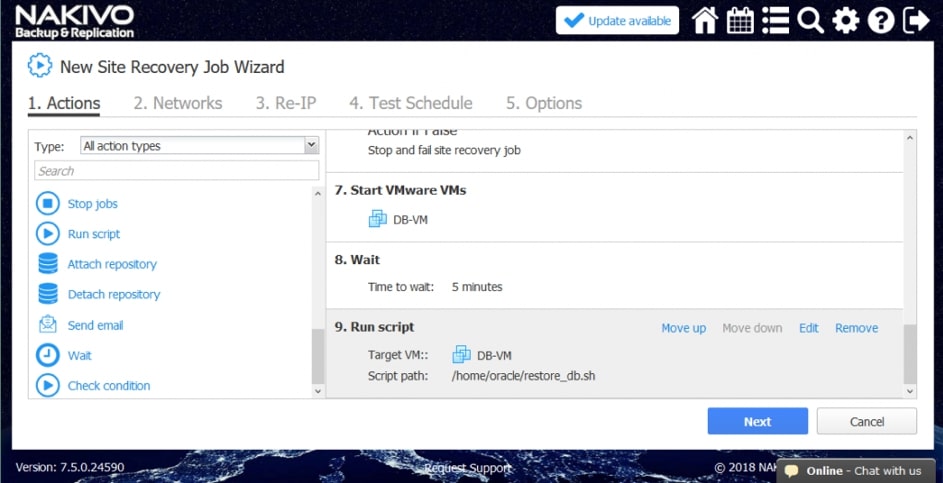
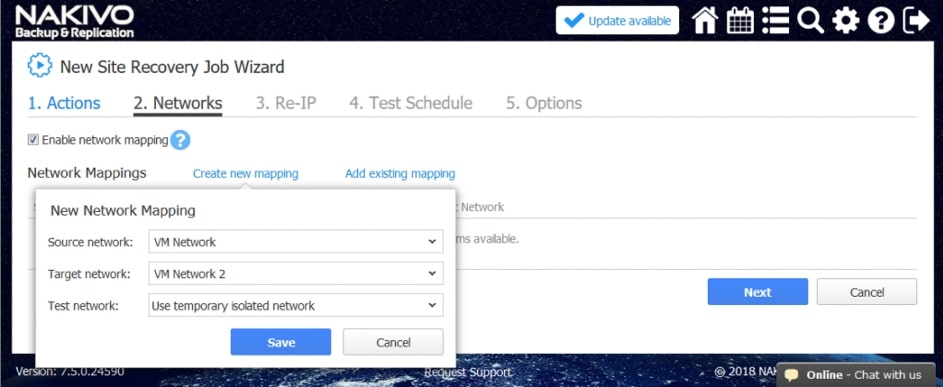
HBS 3: Przyspiesz tworzenie backupu oraz odtwarzanie danych – aby zapewnić sobie niezakłócone funkcjonowanie wszystkich usług i aplikacji
- Deduplikuj dane u źródła: Technologia QuDedup deduplikuje dane u źródła – dzięki zmniejszeniu ogólnej ilości backupowanych danych, redukowane jest również zapotrzebowanie na przestrzeń dyskową oraz transfer. Użytkownicy mogą zainstalować na swoim komputerze narzędzie QuDedup Extract Tool i łatwo przywrócić zdeduplikowane pliki do oryginalnego stanu.
- Ponad 20 zintegrowanych usług chmurowych: QNAP oferuje bezpieczne i elastyczne rozwiązanie do backup w chmurze hybrydowej, a także wsparcie dla TCP BBR Congestion Control – co pozwala na nawet dwukrotne zwiększenie szybkości tworzenia backupu.
CacheMount: Ciesz się dostępem do danych z chmury z minimalnymi opóźnieniami
(The cache feature is coming very soon. Stay tuned for updates.)
- CacheMount integruje NAS-a z popularnymi usługami chmurowymi i pozwala na uzyskiwanie dostępu do danych z chmury z minimalnymi opóźnieniami – dzięki lokalnemu cache’owaniu. Nie ma znaczenia, do jakiej usługi chmurowej podłączony jest NAS – użytkownik może wygodnie używać aplikacji QTS do zarządzania plikami, edytowania ich, odtwarzania, etc.
QuMagie: Zupełnie nowe albumy AI
- QuMagie to następna generacja aplikacji Photo Station, wyposażona w odświeżony interfejs, wbudowaną oś czasu, zintegrowane funkcje AI w dziedzinie organizowania zdjęć, konfigurowalne okładki folderów oraz skuteczną wyszukiwarką – wszystko to czyni z niej kompleksowe rozwiązanie do zarządzania zdjęciami i udostępniania ich.
QNAP NAS obsługuje Fibre Channel SAN
- QNAP NAS z zainstalowaną kartą Fibre Channel może zostać w łatwy sposób podłączony do środowiska SAN, aby zapewnić możliwość korzystania z wysoko wydajnego rozwiązania storage i backup, jednocześnie pozwalając użytkownikom na korzystanie z wielu zalet QNAP NAS, takich jak obsługa migawek, auto-tiering Qtier™ tiering storage, SSD cache, etc.
Multimedia Console integruje wszystkie aplikacje multimedialne QTS
- The Multimedia Console łączy w jednej aplikacji wszystkie narzędzia multimedialne QTS, pozwalając tym samym na wygodniejsze, scentralizowane zarządzanie funkcjami związanymi z obsługą multimediów. Użytkownicy mogą dowolnie wybierać pliki źródłowe dla poszczególnych aplikacji i definiować odpowiednie poziomy uprawnień.
Wygodne usuwanie Qtier SSD RAID Tier
- Użytkownicy mogą wygodnie usuwać nośniki SSD z grupy SSD RAID – aby np. wymienić lub dodać SSD, zmieniać typ SSD RAID lub rodzaj SSD (SATA, M.2, QM2). Można to zrobić w dowolnym momencie, by zwiększyć wydajność auto-tieringu.
Obsługa samoszyfrujących się dysków SED – Self-encrypting Drives
- Samoszyfrujące się dyski (np. Samsung 860 i 970 EVO SSD) pozwalają użytkownikom wykorzystać wbudowaną funkcję szyfrowania bez konieczności używania w tym celu dodatkowego oprogramowania lub wykorzystywania zasobów obliczeniowych NAS-a. Pozwala to na łatwe dodanie dodatkowej warstwy ochrony danych.
Dostępność
QTS 4.4.1 Beta jest już dostępny w Download Center. HBS 3 Beta można pobrać ze strony HBS 3 solution page.
Uwaga: Dostępność funkcji może się zmieniać i mogą one nie być dostępne dla wszystkich produktów.