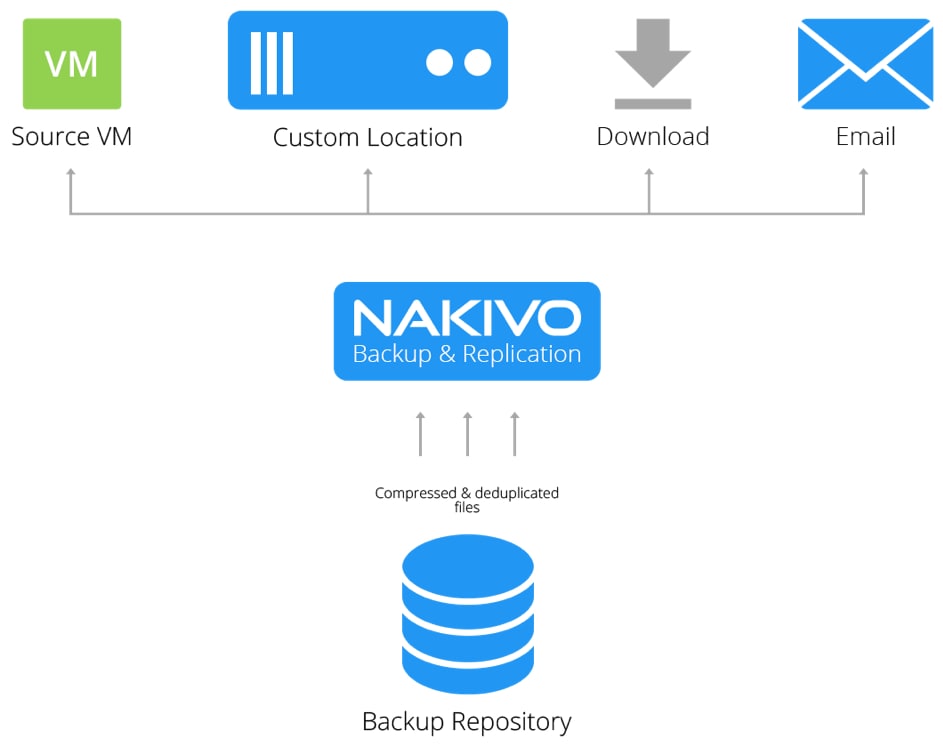
Małe i średnie firmy stają przed wyjątkowymi wyzwaniami, jeśli chodzi o odzyskiwanie danych po awarii. Mają do czynienia z dużo mniejszym budżetem niż większe firmy, a jednocześnie muszą spełniać bardzo podobne oczekiwania dotyczące odzyskiwania danych.
Ponadto personel IT to często mały, ciężko pracujący zespół złożony z trzech lub czterech osób, który obejmuje wszystkie aspekty potrzeb IT organizacji. Wreszcie, zespół staje w obliczu zagrożeń 2018 roku, których zakres jest o wiele szerszy niż kiedykolwiek wcześniej, przede wszystkim ze względu na coraz częstsze i przebieglejsze ataki cybernetyczne.
Większość planów Disaster Recovery w dużych i małych firmach nie została oficjalnie spisana. Tworzy je mieszanka najlepszych pomysłów i starań, które w razie katastrofy sprawią, że zespół IT zaczyna się zastanawiać, czy uda im się ponownie złożyć wszystko w całość, z różnym powodzeniem.
Plan DR dla małych i średnich przedsiębiorstw (MŚP)
Firmy MŚP tworząc politykę „reagowania w czasie awarii” powinny w pierwszej kolejności wziąć pod uwagę to, że dział IT ma bardzo szeroki zakres obowiązków i dodanie kolejnego tak kompleksowego zadania do ich listy nie będzie efektywne. Zamiast pisać złożony plan odzyskiwania danych po awarii, specjaliści IT powinni zacząć od niewielkich działań i skupić się na aplikacjach lub zestawach danych, które są najważniejsze dla organizacji.
Przede wszystkim powinny one podejść do procesu planowania „przywracania po awarii” fragmentów o niewielkich rozmiarach, przy czym każdy fragment musi być realnym, samodzielnym planem. W tym czasie pozostałe plany są opracowywane i ukończone.
Strategia DR dla małych i średnich firm
Począwszy od małych firm strategia ta jest również idealna dla sektora MŚP, o ile firmy wiedzą, od czego zacząć. Miejsce na początek to aplikacja, która jest najważniejsza dla organizacji. Dla przykładu, wiele organizacji odczuje, że poczta e-mail jest aplikacją o znaczeniu krytycznym i będzie chciała ją z powrotem w trybie online tak szybko, jak to możliwe. W przypadku innej organizacji serwer poczty e-mail może znajdować się poza siedzibą firmy, więc inna system, być może oparty na MS-SQL, będzie ważniejszy do odzyskania. W obu przypadkach proces planowania jest podobny. Po pierwsze, architekci muszą zdecydować, jaki jest realny czas przywracania dla tej aplikacji.
Istnieją dwa parametry, które należy zrozumieć: dopuszczalny/tolerowany okres czasu, w którym możemy uznać, że nie będziemy mieli danych biznesowych, często nazywany celem punktu odzyskiwania (RPO) oraz czas maksymalny jaki organizacja zakłada, że system/usługi zostaną przywrócone do działania (RTO).
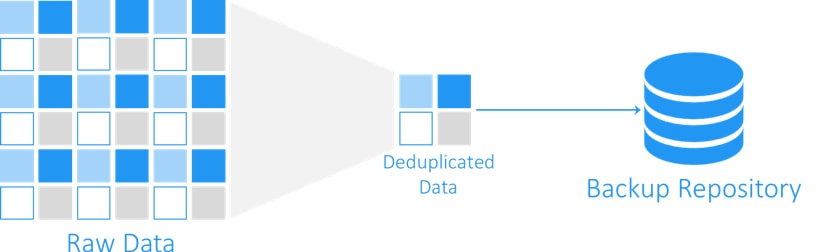
Ograniczenie utraty danych wymaga większego nacisku na zapewnienie ich ochrony, a zapewnienie większej ochrony danych wymaga bardziej wydajnych narzędzi do tworzenia kopii zapasowych, które minimalizują transfer danych. IT potrzebuje rozwiązania, które może tworzyć backup na poziomie pliku podrzędnego, często nazywanego Changed Block Tracking (CBT) lub backupem przyrostowym na poziomie bloku (BLI).
Techniki te umożliwiają organizacji szybkie kopiowanie danych przy jednoczesnej minimalizacji czasu, w którym kopie zapasowe łączą się z aplikacją i minimalizują przepustowość sieci wymaganej do wykonania transferu.
Ponadto, działy IT będą potrzebować swojego rozwiązania, aby zapewnić przejrzysty interfejs dla aplikacji uznanych za krytyczne (Exchange i / lub MS-SQL) w celu wykonania kopii zapasowej wysokiej jakości, podczas gdy aplikacja pozostaje w produkcji. Wreszcie, jeśli chodzi o odzyskiwanie, będą musieli zdecydować, czy na podstawie parametrów RTO będą w stanie zmienić pozycję danych w czasie, aby osiągnąć cel.
Spełnienie parametrów RTO jest funkcją tego, ile danych ma zostać przeniesionych, jaka przepustowość sieci jest dostępna i jak wydajne jest oprogramowanie do tworzenia kopii zapasowych w ruchu danych. W przypadku zbyt dużej ilości danych i niewystarczającej przepustowości, trzeba zwrócić uwagę na techniki takie jak recovery-inplace, gdzie wolumen kopii zapasowych może przedstawiać działający zestaw danych aplikacji bez konieczności przesyłania danych przez sieć.
Przed zakupem jakiegokolwiek nowego oprogramowania lub sprzętu ważne jest, aby dział IT przechodził ten proces z każdą z głównych aplikacji i zestawów danych, ustanawiając dla każdego z nich RPO i RTO, a następnie ocenił, na ile spełnia ich wymagania. Muszą również zrozumieć lukę między obecną rzeczywistością, a pożądaną przyszłością.
Po stwierdzeniu tej luki, planiści IT muszą przeanalizować rozwiązania, które zapewnią im pożądaną przyszłość RPO / RTO. Wreszcie, IT musi przedstawić te ustalenia organizacji, wyjaśniając, że ich wybory to (1) niewydawanie pieniędzy i dostosowywanie oczekiwań do rzeczywistości lub (2) inwestowanie w rozwiązanie, które umożliwi im spełnienie preferowanych celów RPO / RTO.
Metody DR dla Centrów danych małych i średnich firm
W ramach procesu DR, architekci IT muszą zrozumieć, jakie opcje są dla nich dostępne. Istnieje kilka specyficznych funkcji, o których muszą wiedzieć, aby upewnić się, że stanowią część potencjalnego nowego rozwiązania.
Wirtualizuj wszystko
Pierwszym punktem do rozważenia jest wirtualizacja. Zespoły IT w firmach z rynku MŚP powinny próbować wirtualizować wszystkie aplikacje i zestawy danych. Wirtualizacja posiada mnóstwo zalet, których nie można ignorować. Ważne są one w szczególności dla małych i średnich firmach. Większość głównych hypervisor’ów ma wbudowaną technologię CBT lub ułatwia producentowi backupu tworzenie własnej techniki BLI. Wirtualizacja ułatwia odzyskiwanie, ponieważ maszyny wirtualne można stosunkowo łatwo przenieść z jednego serwera fizycznego na drugi.
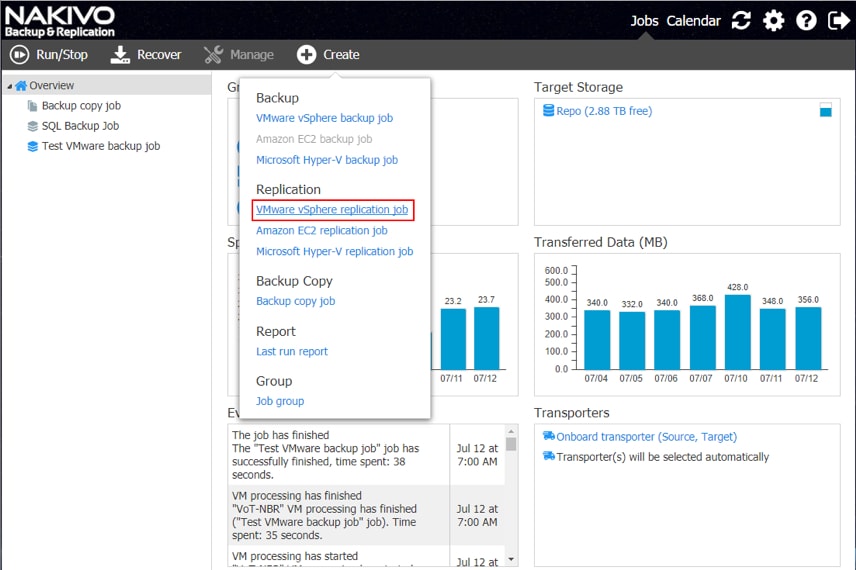
Replikacja vs. Backup
Drugim pytaniem jest, czy organizacja powinna wykorzystywać backup czy replikację. Krytyczne różnice między tymi dwiema technikami to częstotliwość ochrony i poziom retencji. Replikacja zapewnia częstszą ochronę i najkrótsze przechowywanie. Większość organizacji zazwyczaj korzysta z backupu, aby zapewnić ochronę fundamentów w całym przedsiębiorstwie i replikację dla konkretnych aplikacji wymagających wyższego poziomu ochrony i odzyskiwania.
Problem polega na tym, że tworzenie kopii zapasowych i replikacja tradycyjnie pochodzą od różnych dostawców, a zatem trzeba nimi zarządzać niezależnie od siebie. Potrzeba dwóch oddzielnych rozwiązań jest szczególnie frustrująca dla rynku MŚP, który zazwyczaj ma tylko jedną lub dwie aplikacje, które mogą uzasadnić możliwości replikacji. Na szczęście niektórzy producenci oprogramowania do backupu łączą teraz dwie funkcje w jeden produkt i interfejs, umożliwiając zespołom IT w firmach rynku MŚP wybór opcji najbardziej odpowiedniej dla ich środowiska.
Recovery-In-Place (odzyskiwanie na miejscu)
Recovery-In-Place uzupełnia replikację. Dane są nadal chronione w ramach procesu tworzenia kopii zapasowej i są przechowywane w architekturze i formacie kopii zapasowych. Jednak dzięki odzyskiwaniu na miejscu oprogramowanie ma możliwość utworzenia woluminu opartego na ostatniej znanej, dobrej kopii i zamontowania go bezpośrednio w magazynie kopii zapasowych, co oznacza, że aplikacja może powrócić do usługi bez konieczności oczekiwania na przeniesienie danych w sieci. Architektura ochrony danych powinna również być w stanie replikować dane kopii zapasowej, w miarę ich zmiany, w zdalną lokalizację.
Odzyskiwanie w miejscu umożliwia organizacjom uruchamianie maszyn wirtualnych i wskazywanie ich w miejscu przechowywania kopii zapasowych w lokalizacji zdalnej, dzięki czemu aplikacje mogą powrócić do usługi niemal natychmiast po zgłoszeniu awarii.
Kluczową różnicą między tworzeniem kopii zapasowych, a odzyskiwaniem w miejscu i replikacją jest częstotliwość zdarzeń ochrony i czas wymagany do utworzenia woluminu wirtualnego w magazynie kopii zapasowych. W przypadku większości małych i średnich firm miejsce odzyskiwania powinno być odpowiednie dla większości potrzeb związanych z odzyskiwaniem aplikacji.
Podsumowanie
Potrzeba wdrożenia i utrzymania strategii DR jest bardziej realna niż kiedykolwiek w przypadku centrów danych MŚP. Technologie takie jak wirtualizacja, odzyskiwanie granularne i odzyskiwanie danych „na miejscu” obniżają koszty szybkiego odzyskiwania. Wyzwaniem stojącym przed IT jest to, że ich centra danych są już “w ruchu”. Firmy z sektora MŚP do stworzenia planu „odzyskiwania po awarii” powinny pomyśleć nad stworzeniem zestawu planów dotyczących każdej aplikacji z osobna.