Jednym z zagadnień z którym borykają się administratorzy jest to w jaki sposób uprościć i zautomatyzować procesy odpowiedzialne za zapewnianie bezpieczeństwa i ciągłości pracy w firmach. Wyzwanie to szczególnie dotyka większe przedsiębiorstwa charakteryzujące się dynamicznie zmieniającym się środowiskiem IT oraz zarządzaniem rozdzielonym pomiędzy różnych specjalistów. Rozdział pomiędzy osoby o różnych kompetencjach jest naturalny jednak w wypadku braku odpowiednich procedur może prowadzić do obniżenia bezpieczeństwa np. poprzez brak kopii zapasowych dla nowych zasobów.
Wyobraźmy sobie sytuację, w której administrator odpowiedzialny za konfigurację środowiska wirtualnego dodaje maszynę, na której instalowana jest baza danych dla właśnie wdrażanej aplikacji. Ponieważ nie jest jasne czy maszyna zostanie na stałe czy też będzie wykorzystana tylko w czasie testów, administrator nie informuje o tym fakcie specjalisty odpowiedzialnego za backup środowiska wirtualnego.
Po pewnym czasie maszyna z testowej staje się produkcyjną, aplikacja zyskuje na popularności, a baza danych wypełnia się ważnymi rekordami. Pechowo macierz wykorzystywana jako datastore dla środowiska wirtualnego ulega awarii i rozsynchronizowuje się grupa RAID w którą połączone były dyski. Specjalista od backupu przystępuje do odtwarzania maszyn w środowisku zapasowym, pomijając kwestie czasu potrzebnego na odtwarzanie środowiska i brak ciągłości operacyjnej firmy, wszyscy są dobrej myśli, bo przecież backup środowiska był wykonywany i mamy się z czego odtwarzać. Na koniec dnia okazuje się, że działa wszystko poza nową aplikacją i wymaganą przez nią bazą danych która od czasu wdrożenia stała się jednym z ważniejszych narzędzi.
Oczywiście ten scenariusz można uznać za przekoloryzowany, który w organizacji o odpowiednich procedurach nie mógłby mieć miejsca, ale przypadków, w których ktoś zapomniał lub świadomie nie wykonał backupu, bo przecież u nas nic złego się nie wydarzy znaleźć można znacznie więcej i dotyczą one zarówno mniejszych firm jak i dużych korporacji.
Automatyczny backup i replikacja – Policy Based Data Protection
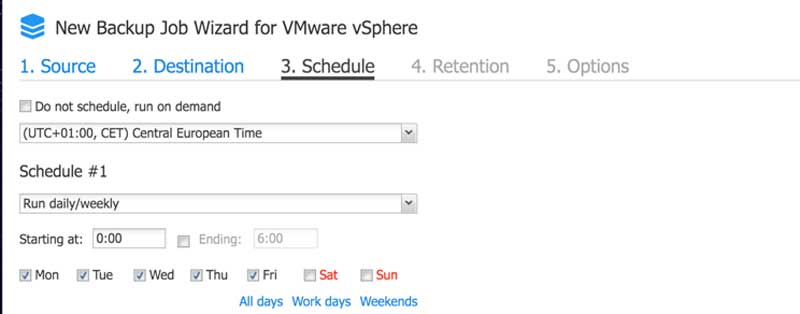
Automatyzacja zadań backupu i replikacji to jeden z elementów na który rozwiązanie Nakivo kładzie duży nacisk. Podstawą planowania procesów automatycznych jest odpowiednie ustawienie harmonogramów kopii zapasowych lub replikacji, w tym celu Nakivo oprócz możliwości utworzenia kilku harmonogramów w jednym zadaniu, udostępnia tzw. Calendar Dashboard dzięki któremu widzimy już zaplanowane zadania i łatwiej planować okna serwisowe.
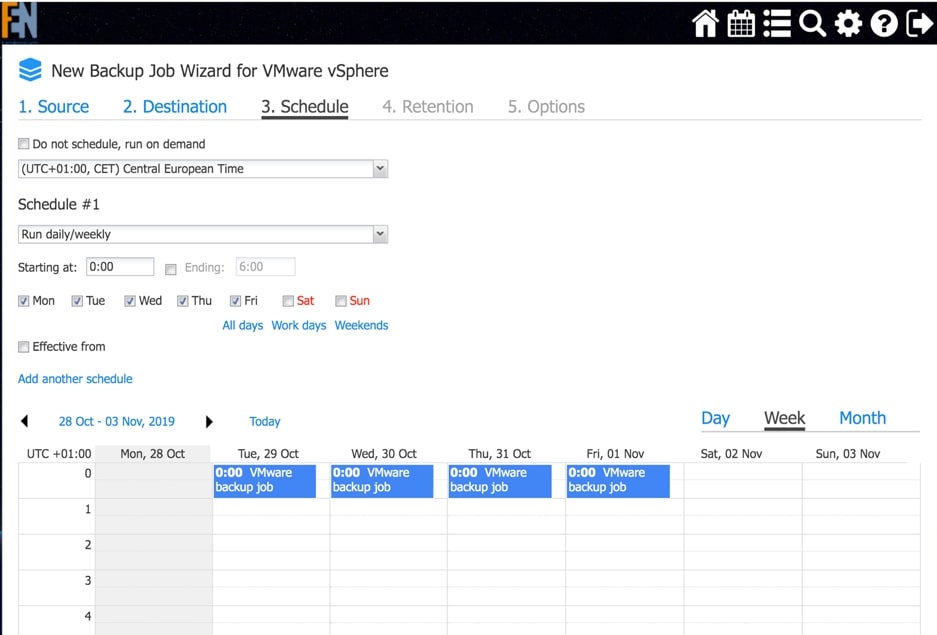
Rys. 1 Widok kalendarza z perspektywy nowo tworzonego zadania.
Globalny widok kalendarza jest dostępny również bezpośrednio z menu głównego, na nim możemy nie tylko podejrzeć, ale również edytować zadania lub generować raporty.
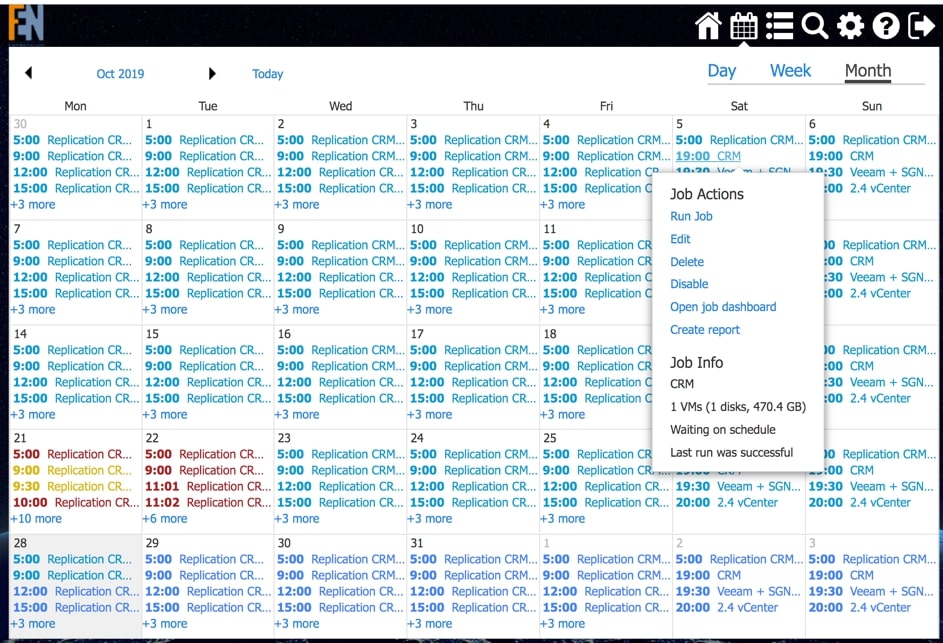
Rys. 2 Widok kalendarza globalny umożliwiający edycję i generowanie raportów dla już zaplanowanych zadań.
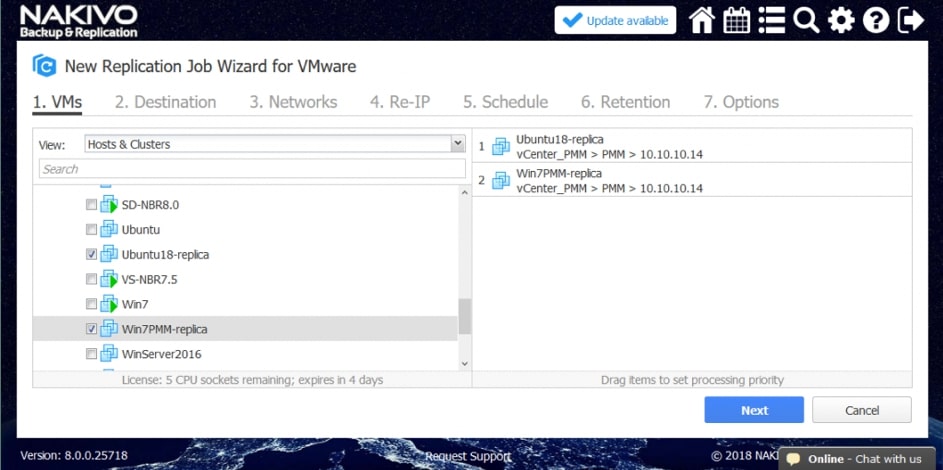
Kluczowym elementem obok odpowiedniego zaplanowania okien serwisowych jest jednak możliwość realizacji zadań backupu nie dla pojedynczych maszyn, ale dla całych ich grup lub kontenerów, w których się znajdują. W tym celu w trakcie tworzenia zadania mamy do wyboru kilka opcji widoku środowiska, które zamierzamy backupować. Widok podstawowy pozwala nam wybrać konkretne maszyny, kontenery lub hosty, których zasoby zamierzamy backupować lub replikować.
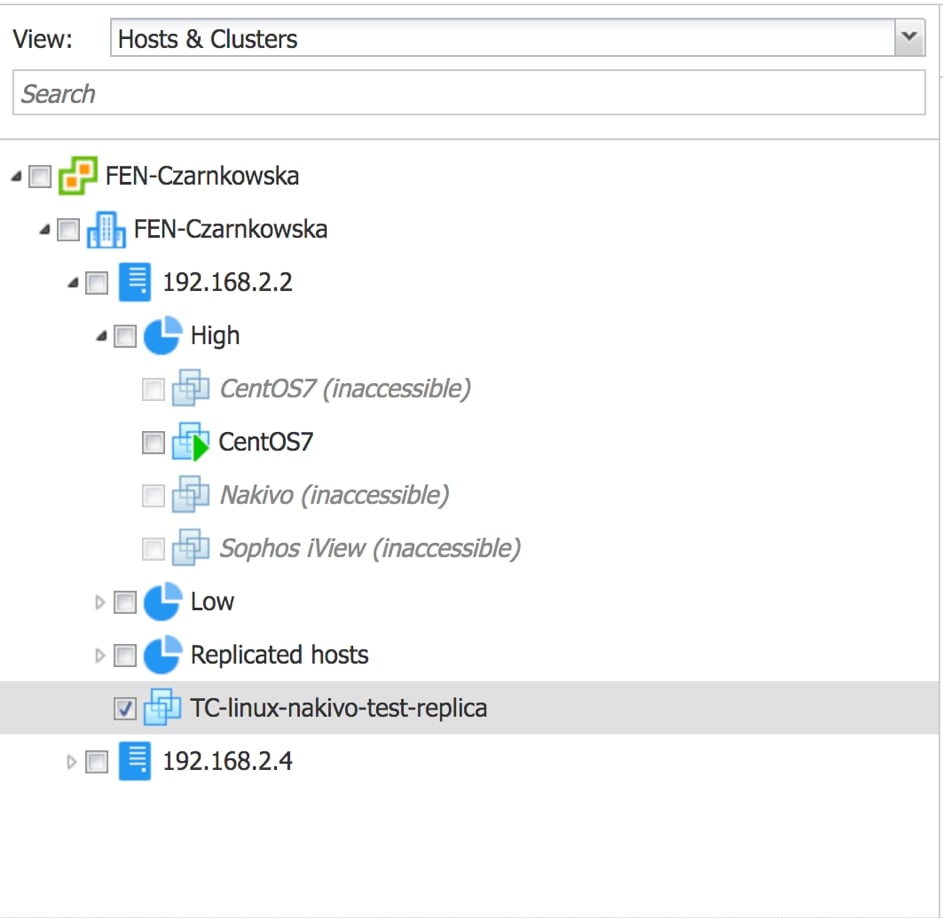
Rys. 3 Widok podstawowy wyboru maszyn do zadania backupu lub replikacji: Hosts&Clusters
Widok VMs&Templates, umożliwia nam wybranie maszyn w zależności od ich przypisania do DC na poziomie vCenter, bez względu na to na którym z hostów działają maszyny, sprawdzi się w środowiskach, gdzie maszyny są przenoszone dynamicznie.
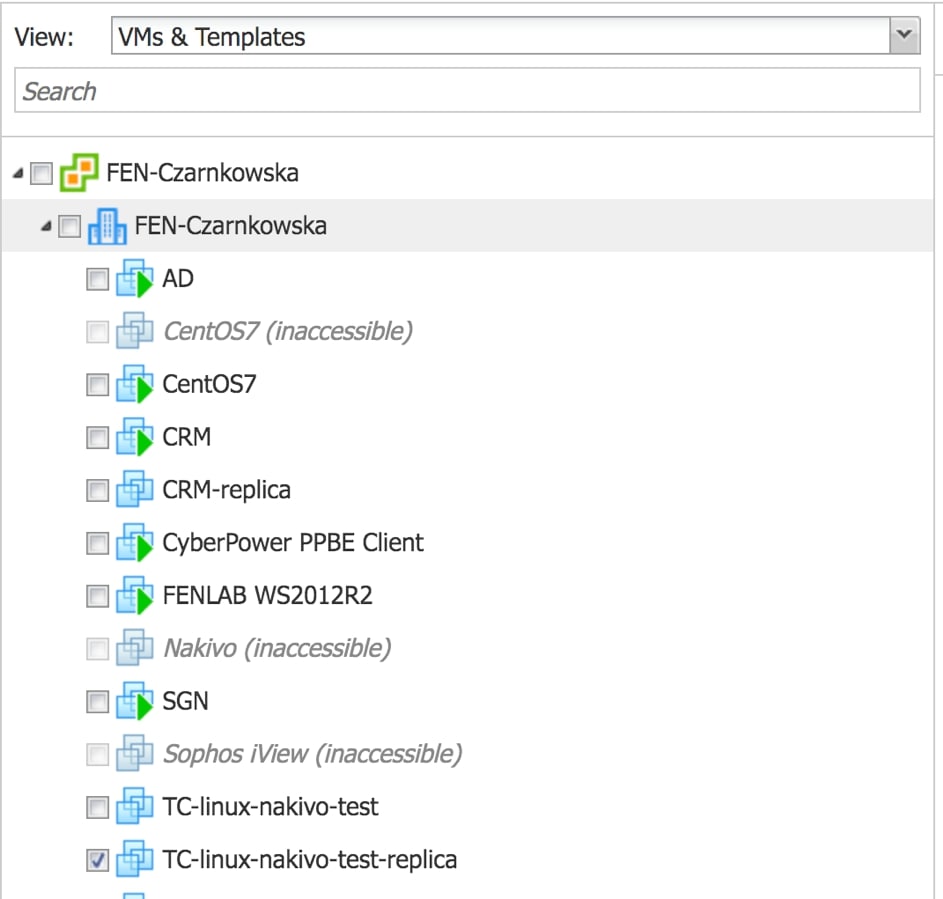
Rys. 4 Widok wyboru maszyn do zadania backupu lub replikacji: VMs&Templates
Najciekawszym jest jednak tryb Policy based, w momencie wywołania harmonogramu, zanim backup lub replikacja się rozpoczną administrator może wcześniej zaplanować jakie warunki mają być spełnione, aby zadanie zostało zrealizowane. Warunki można ze sobą łączyć, tworząc bardziej złożone scenariusze uzależniające wykonanie zadania od takich elementów jak: nazwa maszyny wirtualnej, lokalizacja maszyny wirtualnej, datastore wykorzystywany przez maszynę wirtualną, rozmiar maszyny wirtualnej, a także jej aktualny stan. Zastosowanie warunków umożliwia utworzenie zadań, które będą w zautomatyzowany sposób weryfikowały w trakcie wywołania harmonogramu czy nowe zasoby wymagające ochrony nie pojawiły się w naszej infrastrukturze, a jeżeli tak aby je objąć ochroną automatycznie.
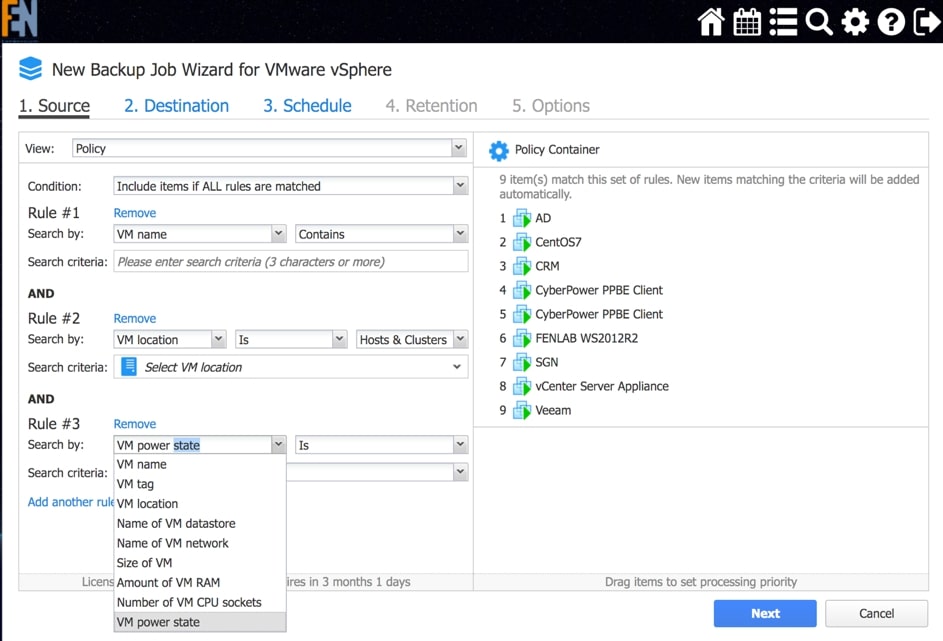
Rys. 5 Widok wyboru maszyn do zadania backupu lub replikacji: Policy
Takie podejście zabezpiecza nas przed wspomnianym wcześniej przykładem, w którym nie było komunikacji pomiędzy specjalistami od środowiska wirtualnego i backupu, ponieważ nowa maszyna zostałaby w tym przypadku automatycznie wykryta i dodana do zadania a jej ochrona zostałaby zapewniona.
Automatyczna weryfikacja kopii zapasowej – Automatic Screenshot Verification
Kolejnym pytaniem, które zadajemy sobie czasami w kontekście rozwiązań do backupu jest to czy nasza kopia zapasowa jest użyteczna, czyli czy będziemy mieli z czego się odtwarzać jeżeli będzie taka konieczność. Dobrą praktyką jest cykliczne testowanie backupów pod kątem możliwości odtworzenia i uruchomienia chronionych maszyn. Nakivo upraszcza jednak również ten proces, dzięki Automatic Screenshot Verification, funkcja ta ma za zadanie w sposób całkowicie automatyczny po wykonaniu zadania backupu przeprowadzić próbę odtwarzania chronionej maszyny.
W trakcie procesu Nakivo wykorzystuje protokół iSCSI żeby backup maszyny podpiąć bezpośrednio z deduplikowanego i skompresowanego repozytorium do hosta wskazanego jako cel odtwarzania, w ten sposób maszyna uruchamiana jest w trybie tymczasowym bez kopiowania jej zawartości na odtwarzanego hosta. Po odtworzeniu maszyny wykonywany jest zrzut ekranu z konsoli środowiska wirtualnego dla odtworzonej maszyny, zrzut taki może zostać wysłany przez email lub dodany do raportu dotyczącego chronionego zasobu.
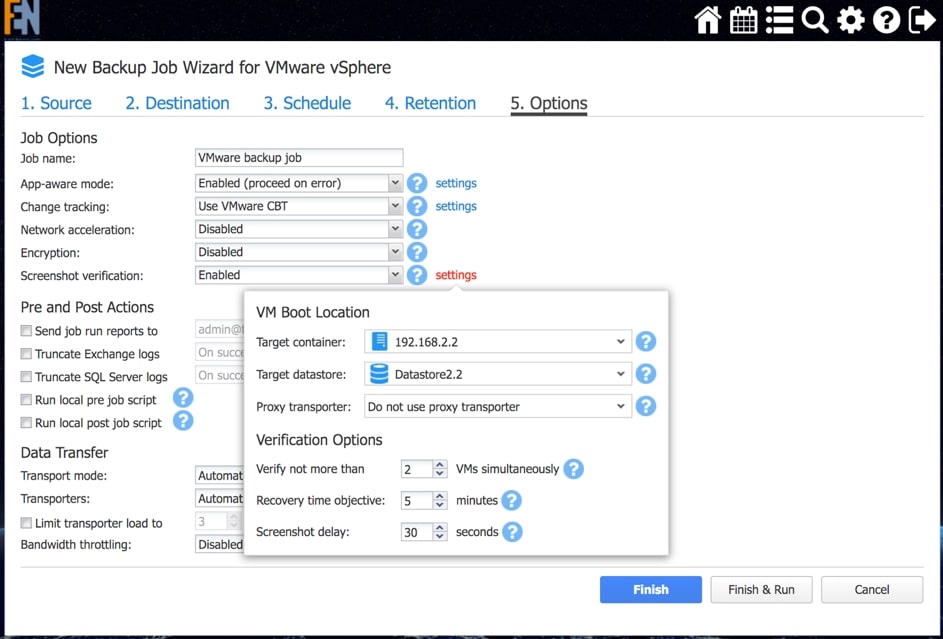
Rys. 6 Konfiguracja funkcji Automatic Screenshot Verification.
W trakcie konfiguracji funkcji możemy wskazać zasób, na który testowe odtwarzanie będzie wykonywane, ile maszyn możemy przetestować jednocześnie, aby uniknąć nadmiernego obciążenia środowiska, jakie będzie opóźnienie wykonania zrzutu ekranu od uruchomienia maszyny oraz jaki jest akceptowalny czas odtwarzania.
Automatyczna kopia backupu – Backup Copy
Dobre praktyki backupu jako wzór często wskazują strategię 3-2-1, czyli przechowywanie minimum 3 kopii zapasowych, na przynajmniej 2 nośnikach(urządzeniach) przy czym 1 z nich powinno znajdować się innej lokalizacji. Opisałem już jak zautomatyzować procesy backupu korzystając z Nakivo, nie odnieśliśmy się jednak jeszcze do możliwości archiwizacji wykonanego backupu lub jego przechowywania w innej lokalizacji. Jedną z metod którą można by wykorzystać jest stworzenie kilku zadań backupu wraz ze wskazaniem różnych repozytoriów jako obiektów docelowych.
Nakivo jako repozytorium może wykorzystać dyski lokalne modułu transporter (jeden z modułów funkcjonalnych rozwiązania), dyski podłączone do transportera po iSCSI, dyski sieciowe wykorzystując protokoły CIFS lub NFS oraz repozytoria chmurowe poprzez instalację modułu transporter w środowiskach AWS, Google Cloud lub Azure.
Takie podejście ma swoje wady, kilka zadań backupu realizowanych na tej samej maszynie powoduje niestety dodatkowe obciążenie hostów produkcyjnych koniecznością wykonywania wielokrotnie migawek chronionej maszyny, w środowiskach o znacznym obciążeniu lub gdy chcemy ograniczyć ilość przesyłanych danych istnieje możliwość wykonania kopii z już wykonanego backupu, dzięki czemu środowisko produkcyjne obciążane jest tylko raz, a jednocześnie dane możemy przechowywać w wielu lokalizacjach.
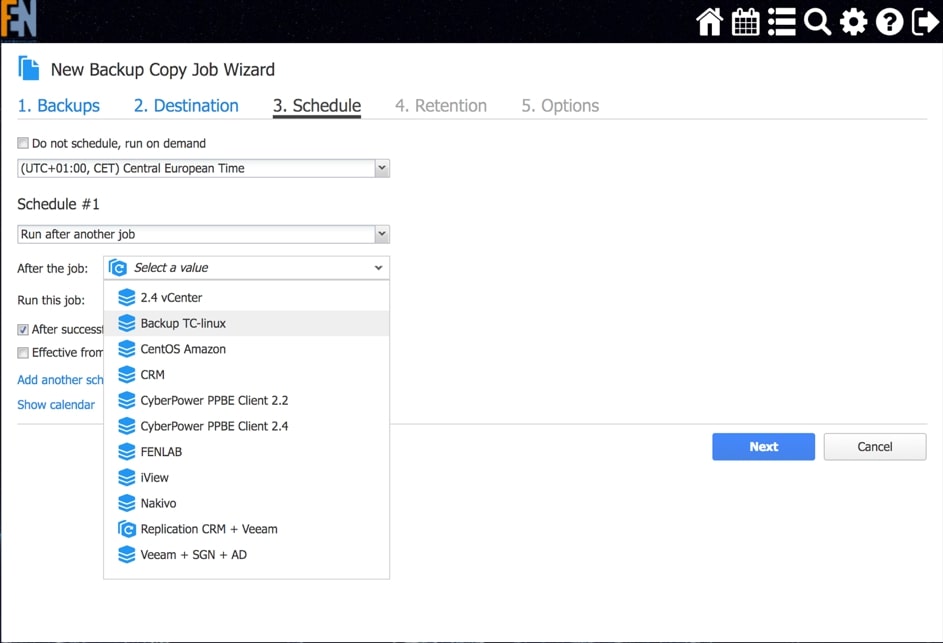
Rys. 7 Konfiguracja funkcji Backup Copy.
W ramach konfiguracji funkcji Backup Copy, możemy wybrać opcję tworzenia kopii wg ustalonego (odrębnego harmonogramu) lub uzależnić wykonanie kopii od już wykonywanych zadań, automatyzując proces archiwizacji. W ten sposób ukończone prawidłowo zadanie backupu danej maszyny może wywoływać zadanie utworzenia kopii, w którym również możemy skorzystać z wcześniej opisanego mechanizmu Screenshot Verification aby upewnić się, że ta kopia również będzie użyteczna.
Planowanie i testowanie procesów odtwarzania – Site Recovery
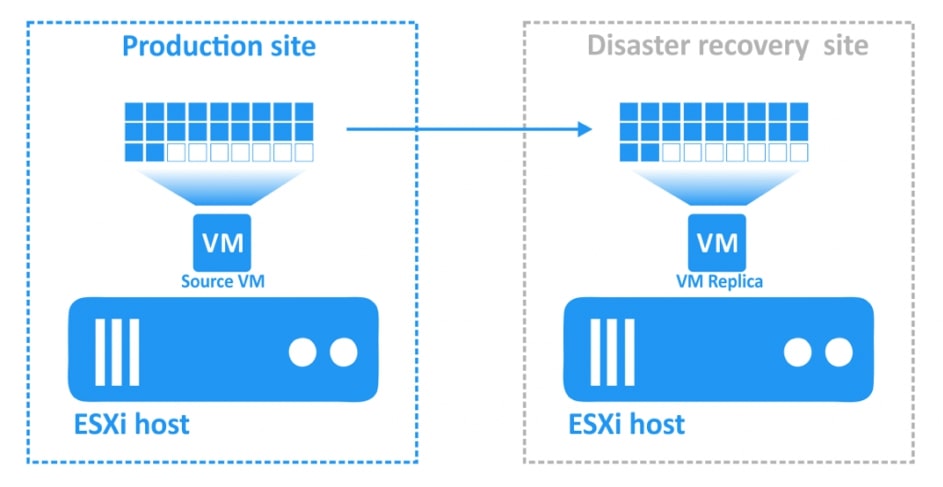
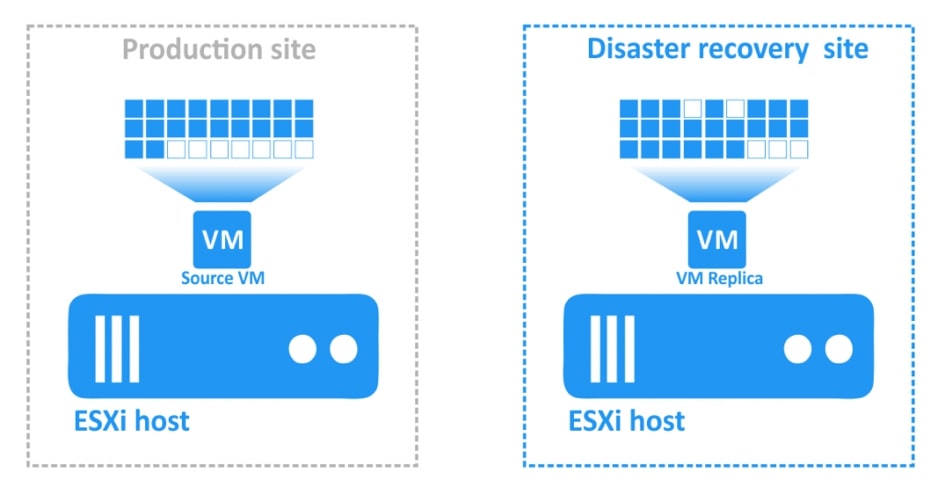
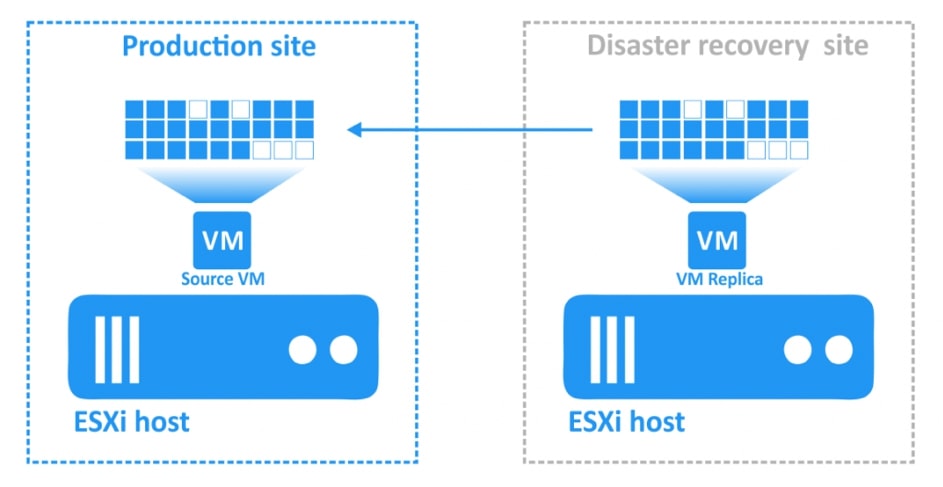
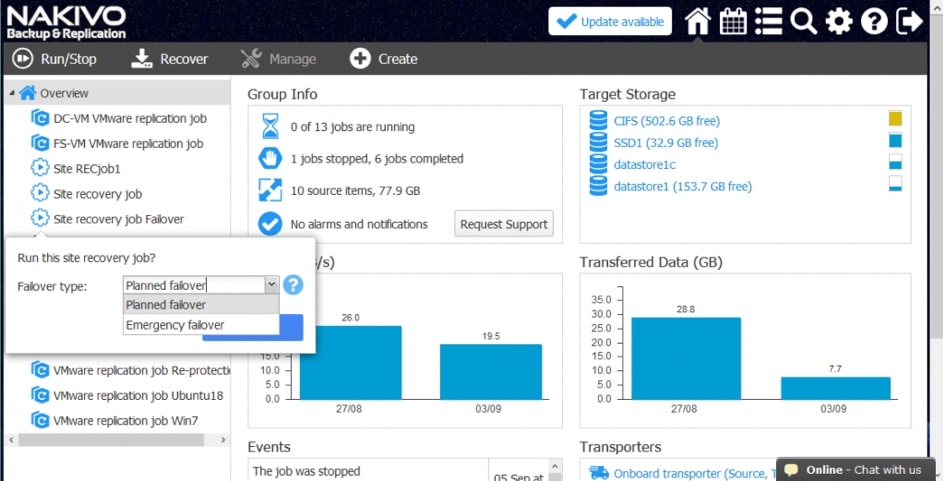
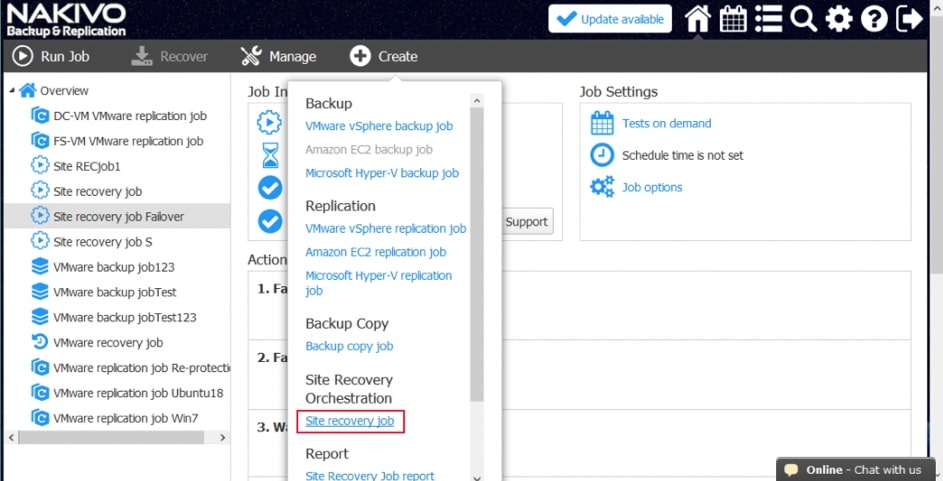
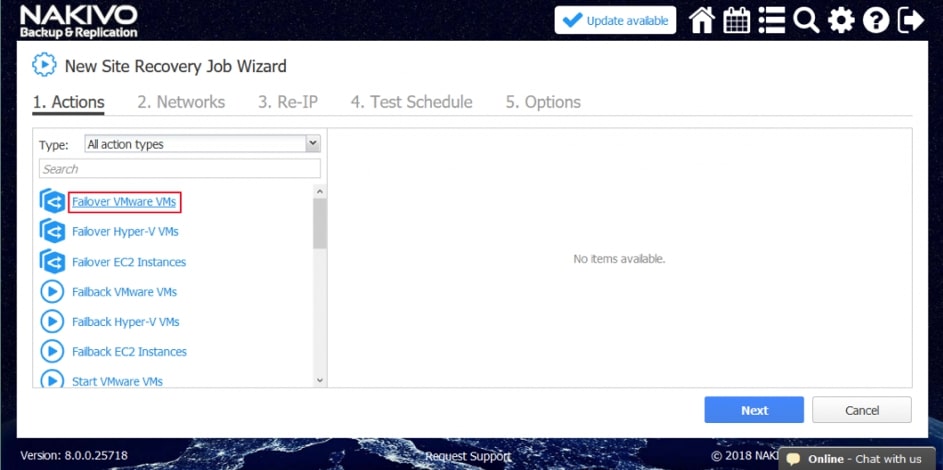
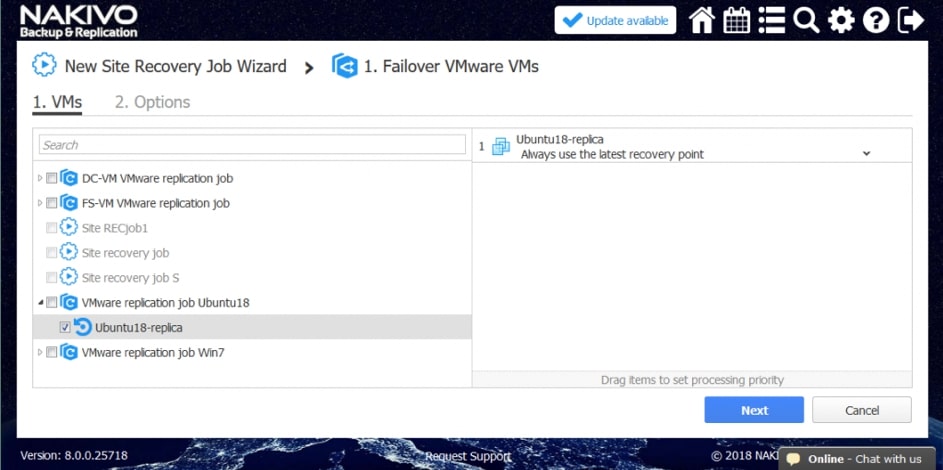
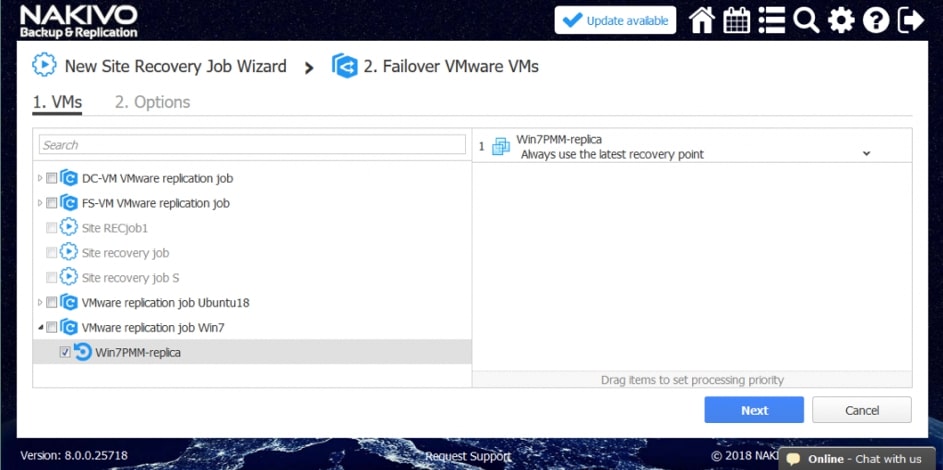
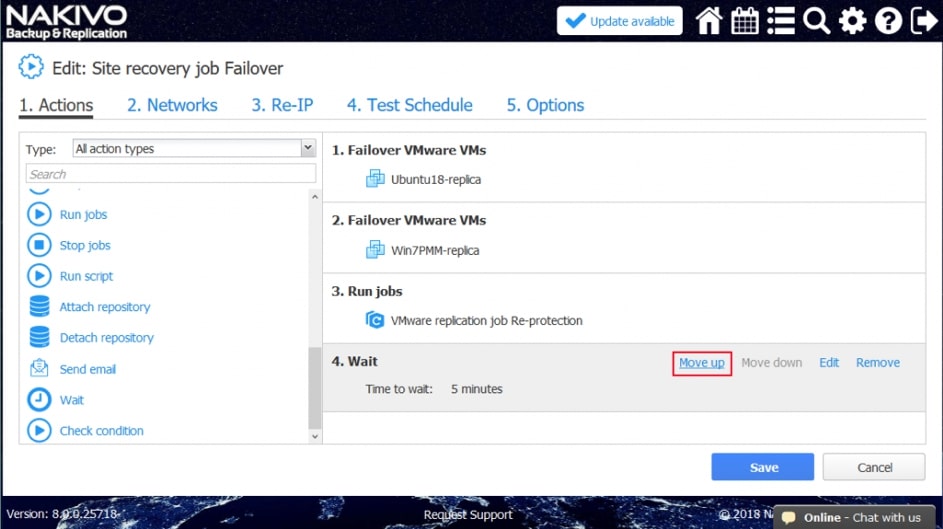
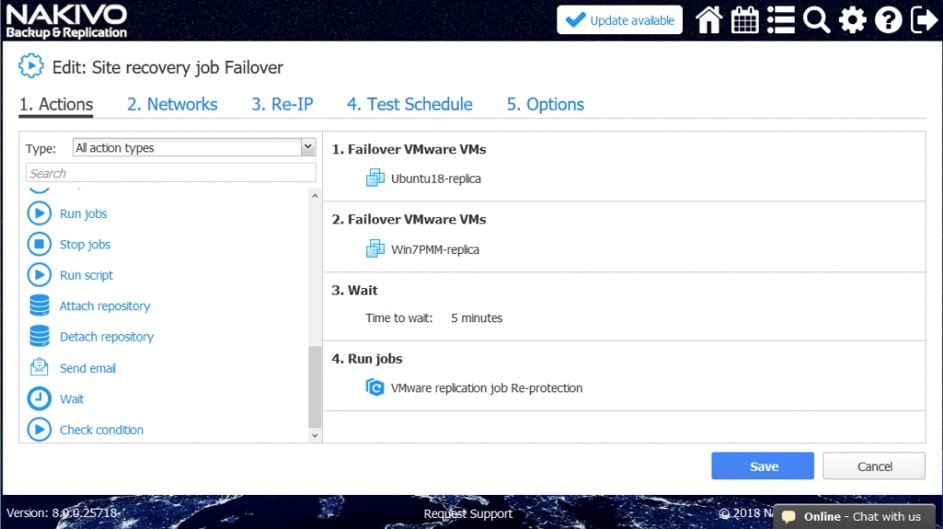
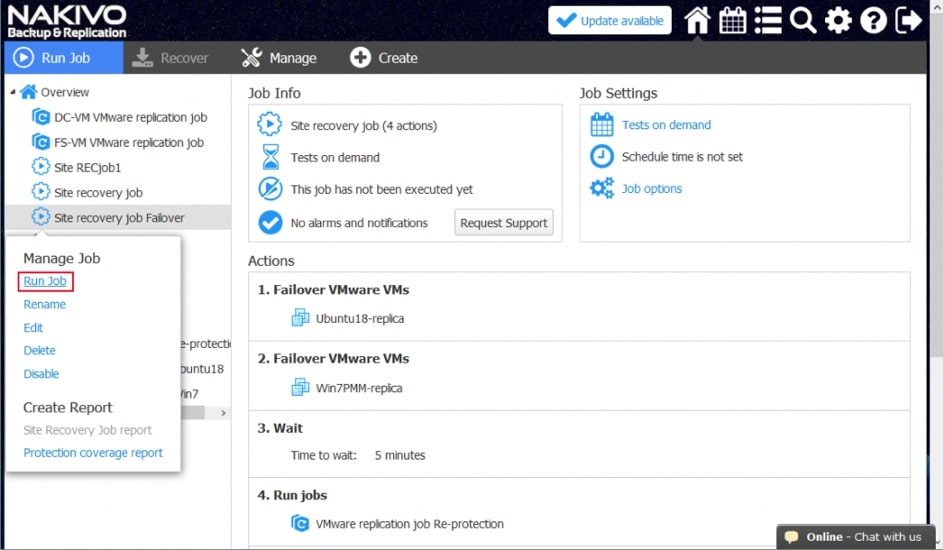
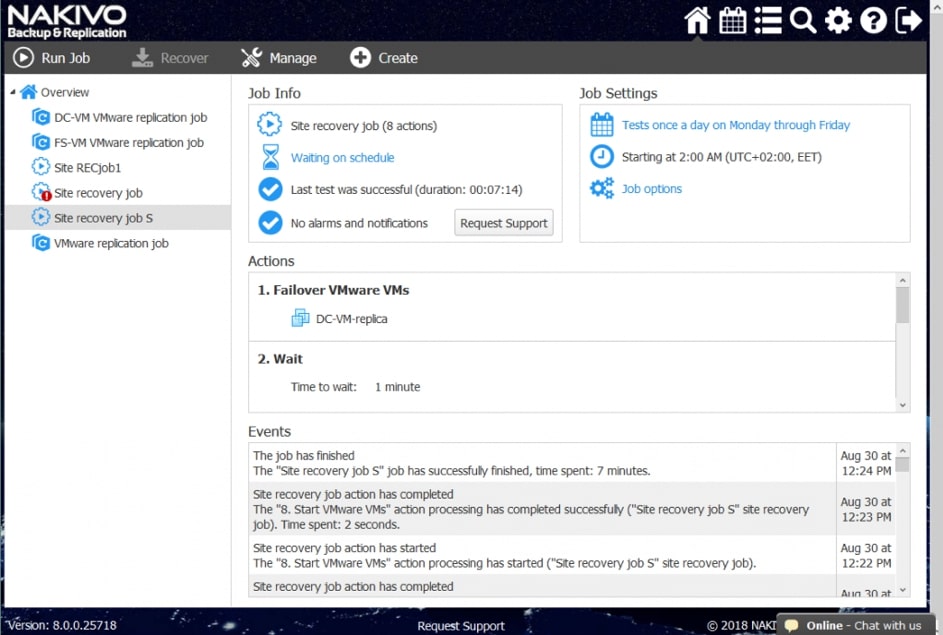
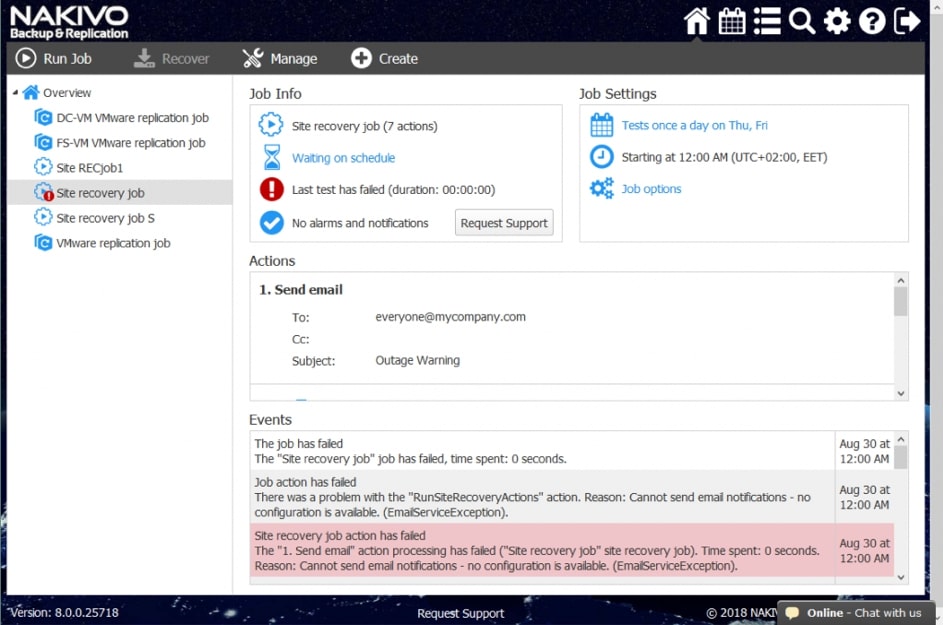
Zwieńczeniem automatyzacji procesów backupu i odtwarzania w Nakivo jest mechanizm Site Recovery. Mechanizm Site Recovery umożliwia utworzenie zestawu akcji, które mają być realizowane przez oprogramowania w określonej przez administratora kolejności w wypadku gdy dojdzie w środowisku do awarii, planowany jest serwis wirtualnej infrastruktury lub musimy udowodnić dla potrzeb wszelkiego rodzaju audytów wewnętrznych i zewnętrznych jak skutecznie i szybko jesteśmy w stanie odtworzyć nasze środowisko.
Proces tworzenia scenariuszy Site Recovery zaczynamy od planowania i jest to jeden z najważniejszych elementów od którego będzie zależała skuteczność i szybkość naszej procedury odtwarzania. Dodatkowo scenariusz będzie indywidualny w każdym środowisku i w dużej mierze będzie zależał od tego co chcemy uzyskać w jego wyniku.
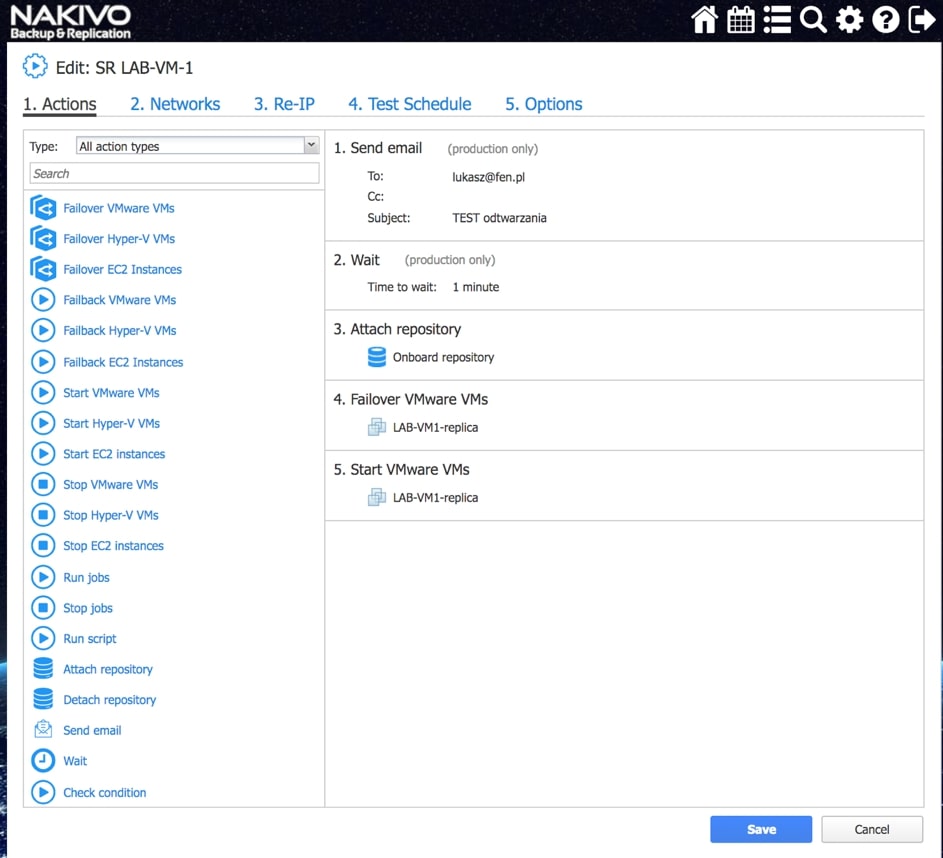
Rys. 8 Tworzenie Scenariusza Site Recovery
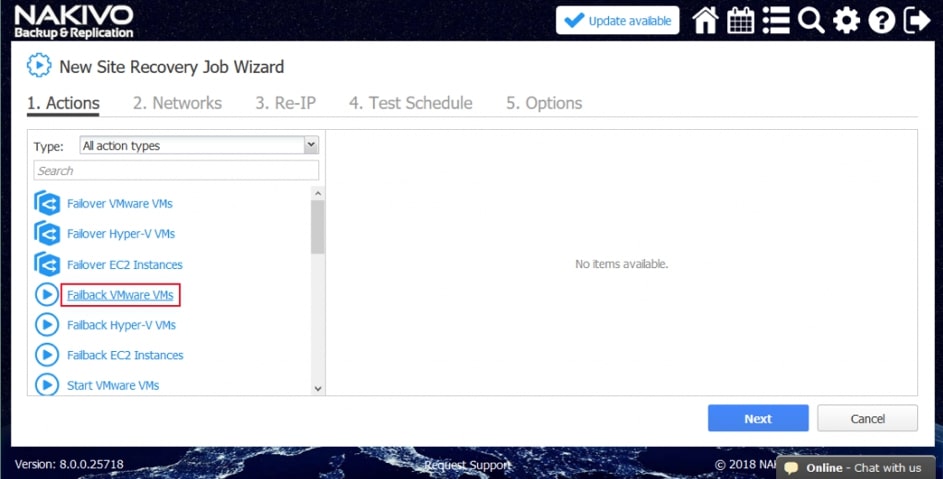
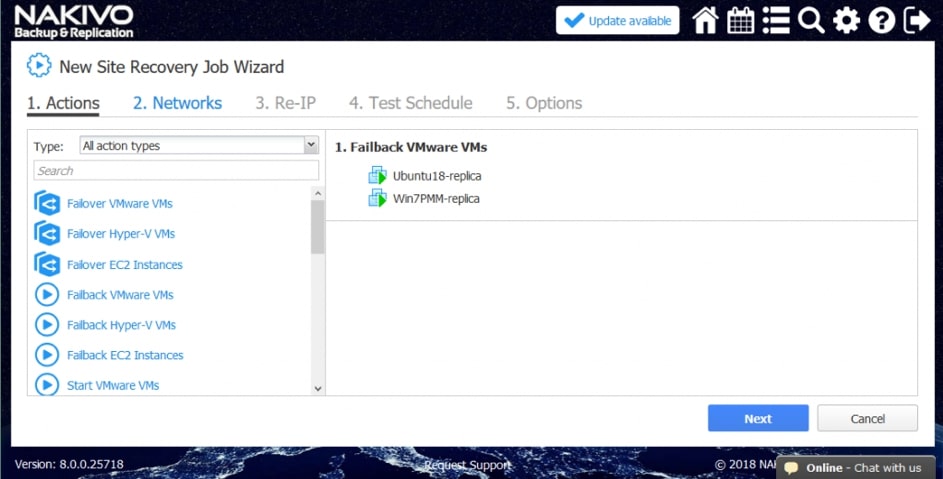
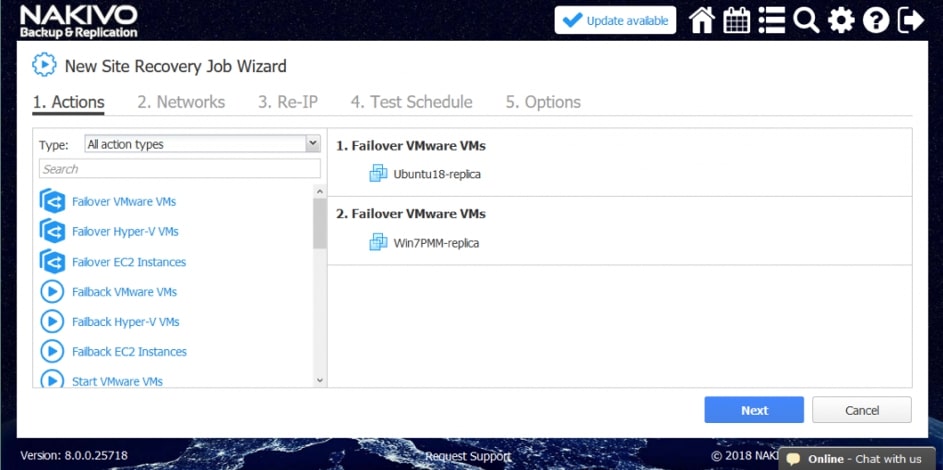
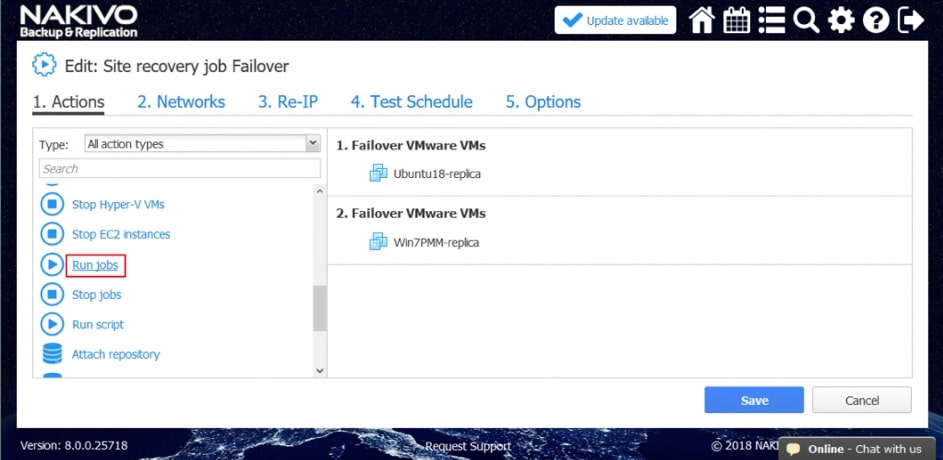
Wśród akcji dostępnych w ramach tworzenia scenariuszy Site Recovery znajdziemy akcje wspólne, tj. takie które można wykonywać niezależnie od chronionego środowiska oraz akcje dedykowane poszczególnym środowiskom jak Vmware czy Hyper-V.
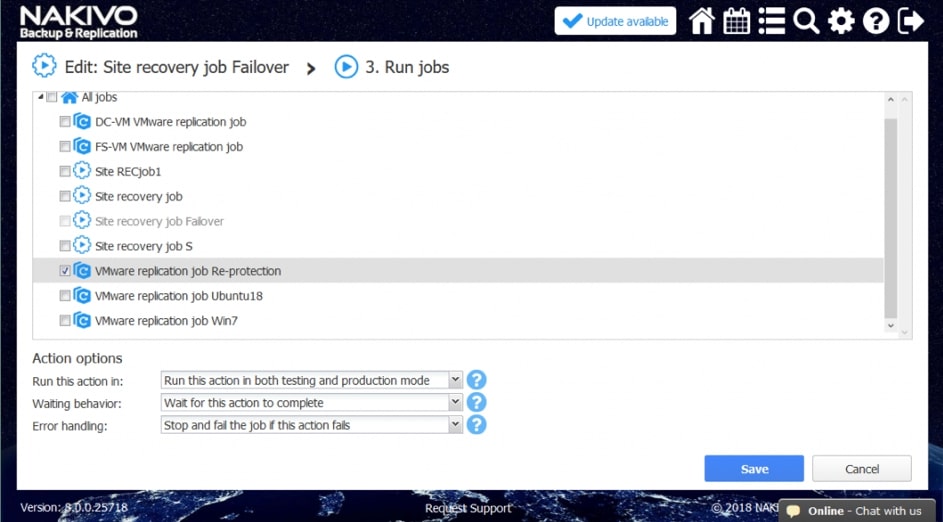
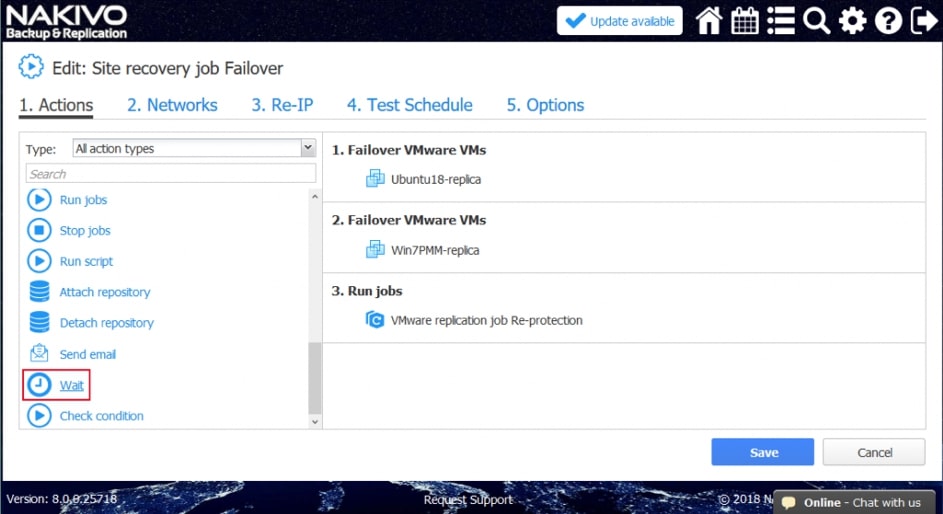
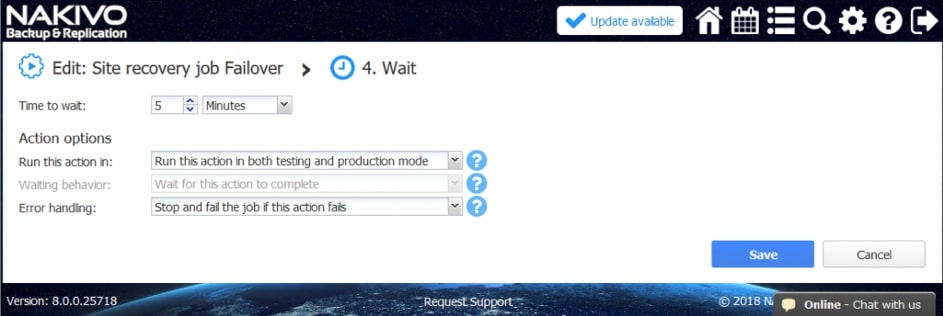
Przykładowe akcje wspólne to: wywołanie lub zatrzymanie wcześniej utworzonych zadań, wykonanie skryptu, podłączenie lub odłączenie repozytorium, wysłanie wiadomości email (w celu poinformowania o realizowanej procedurze odtwarzania), odczekanie określonego czasu lub sprawdzenie warunków dotyczących chronionego środowiska.
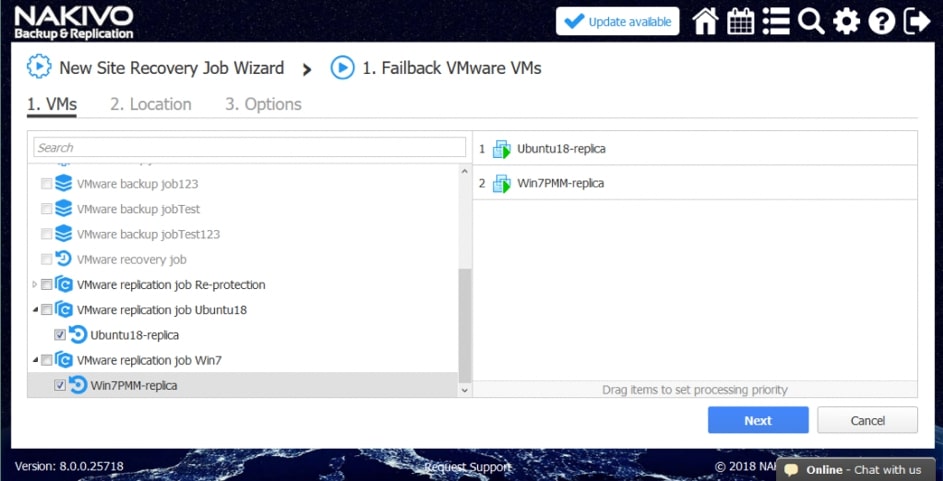
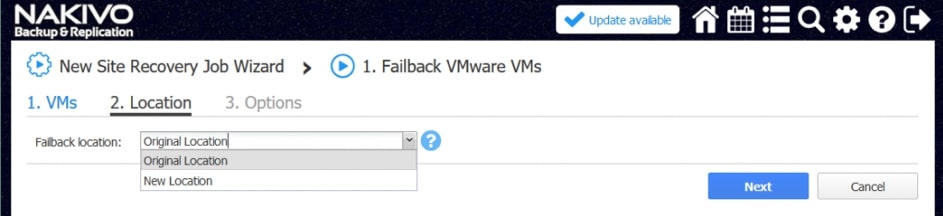
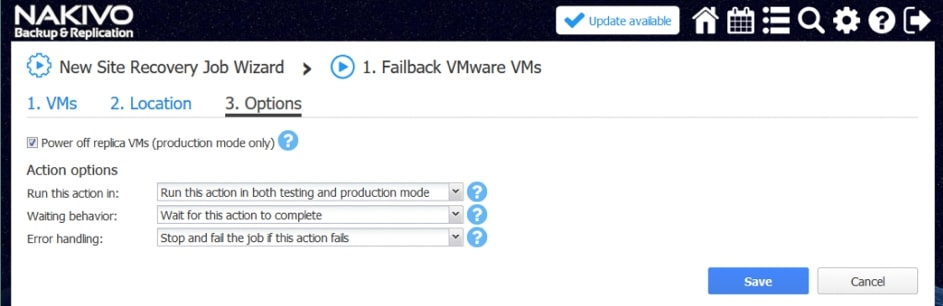
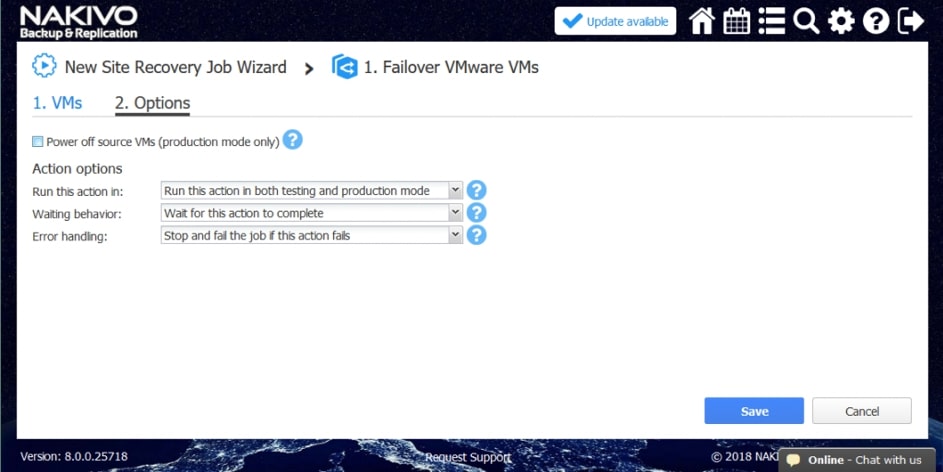
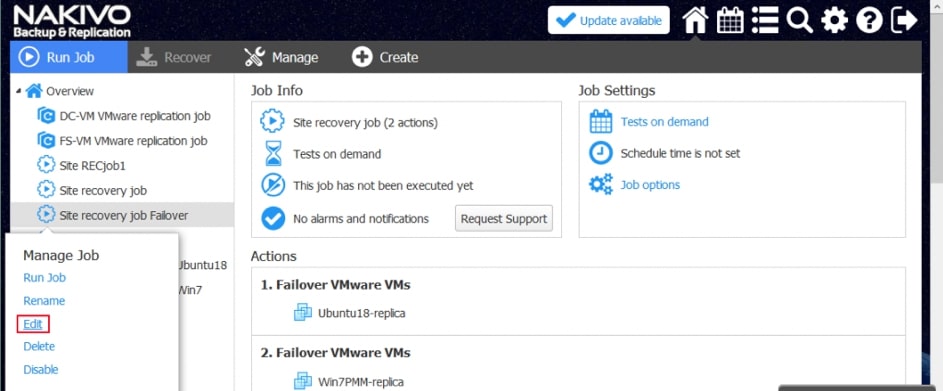
Przykładowe akcje dedykowane dla środowiska to: procedura Failover, czyli przeniesienia maszyn produkcyjnych na środowisko zapasowe, w ramach procedury możemy wyłączyć maszyny produkcyjne jeżeli działały w momencie uruchomienia procedury oraz uruchomić maszyny na środowisku zapasowym, włączając w to re-mapowanie niezbędnych interfejsów sieciowych oraz re-adresacje maszyn; procedura Failback, czyli odwrotność procedury Failover mechanizm pozwalający zsynchronizować maszyny zapasowe z maszynami produkcyjnymi i przerzucenie obciążenia z powrotem na środowisko produkcyjne; uruchomienie lub zatrzymanie określonych maszyn w środowisku.
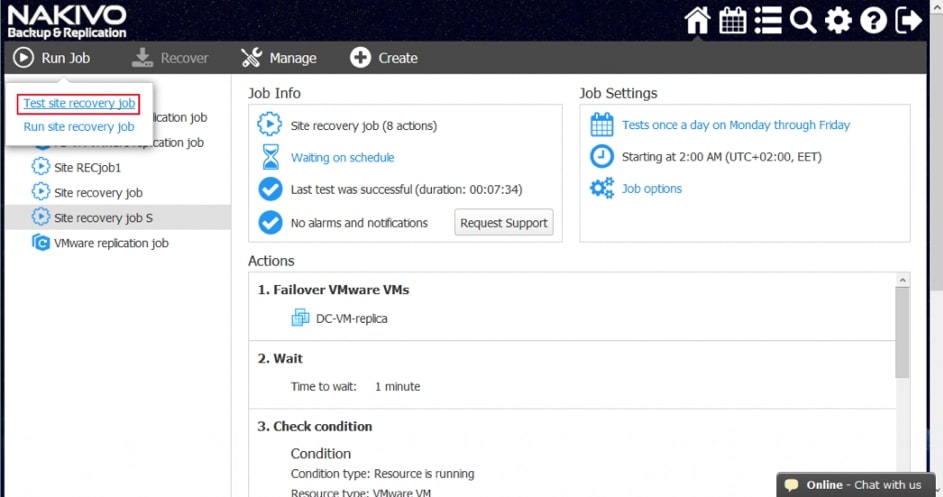
Akcje wspólne i charakterystyczne dla środowiska łączymy w ciąg zdarzeń, który zostaje wywołany podczas testowania lub ręcznego wywołania procedury przez administratora.
Poszczególne z akcji mają możliwość określenia, które z nich będą wykonywane tylko w czasie awaryjnego odtwarzania, a które w czasie procedury testowej, dzięki czemu możemy zasymulować odtwarzanie środowiska bez szkody dla środowiska produkcyjnego.
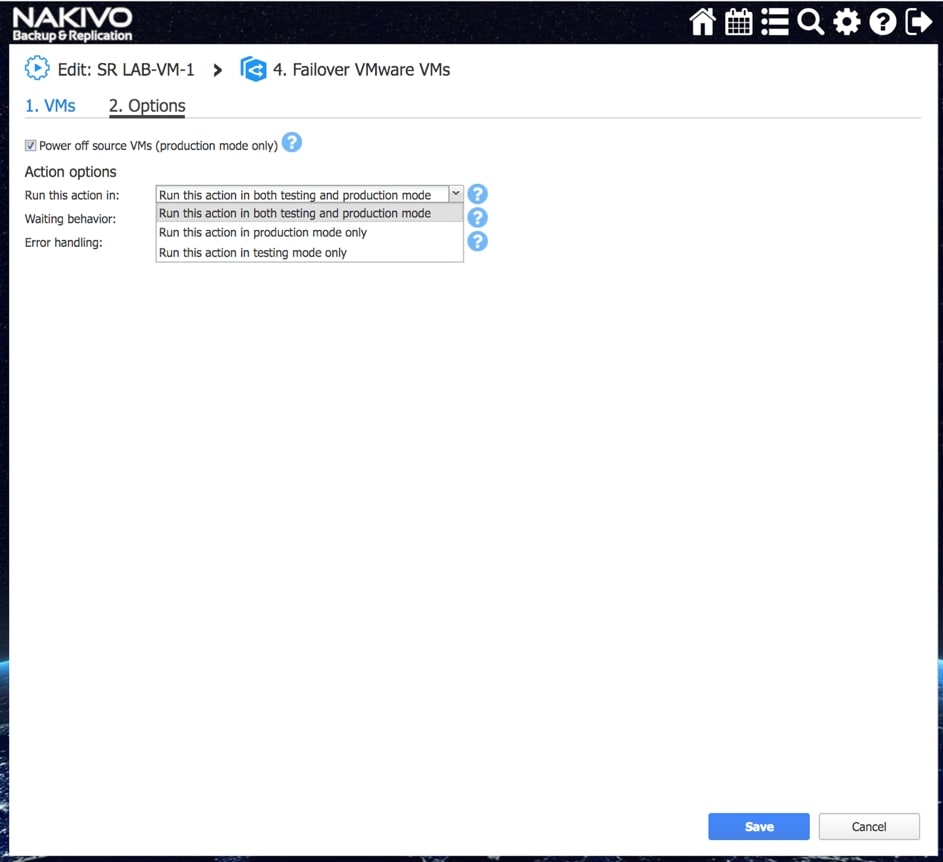
Rys. 9 Uzależnienie wykonania akcji w ramach procedury odtwarzania od warunków uruchomienia procedury Site Recovery.
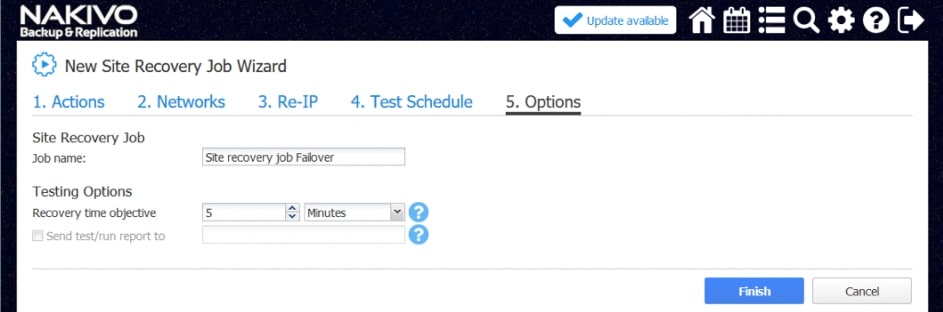
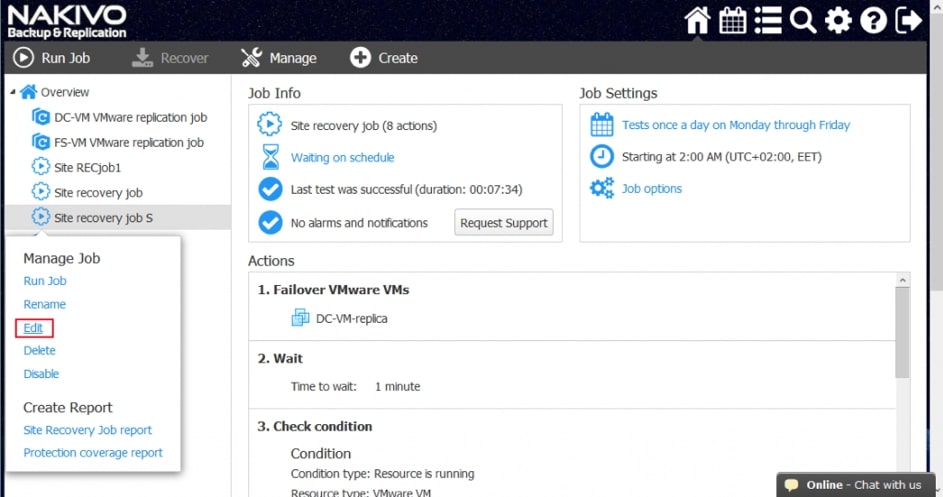
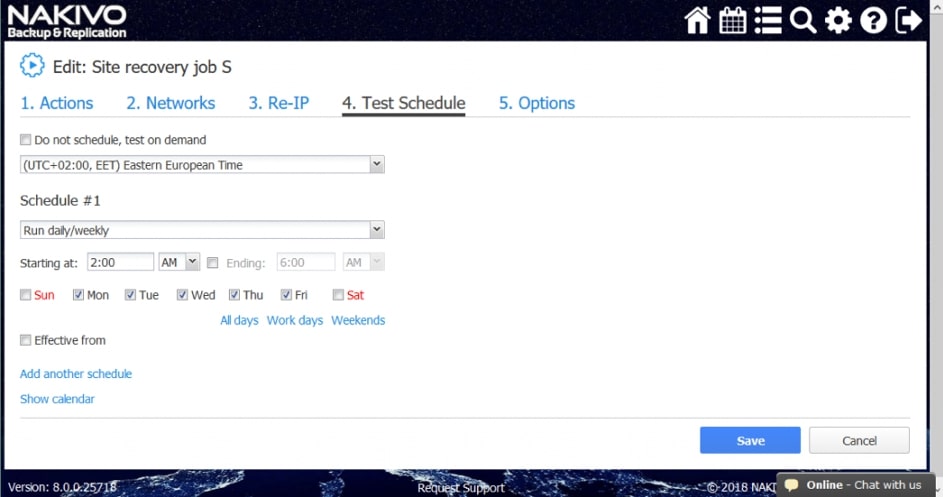
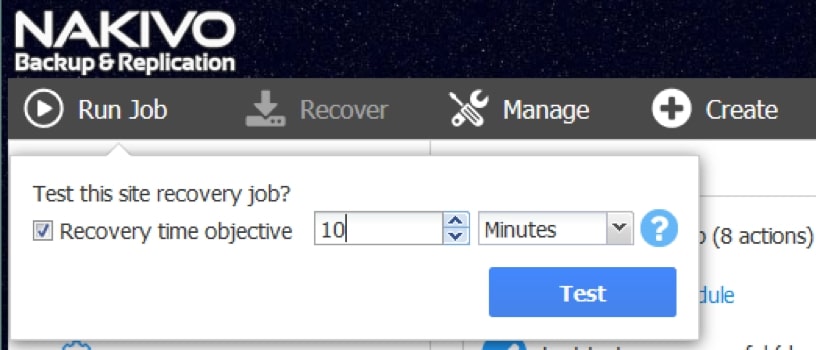
Testowanie odtwarzania może odbywać się zgodnie z zaplanowanym przez administratora harmonogramem, co zapewnia cykliczną aktualizację danych dotyczących skuteczności procedury w kontekście planowanego RTO (planowego czasu odtworzenia) dla naszego środowiska.
P2V czyli szybkie odtwarzanie serwerów fizycznych
Ostatni akapit nie jest szczególnie związany z automatyzacją procesów backupu ale mimo wszystko warto poświęcić mu jeszcze chwilę. Nakivo od początku swojego istnienia skupiło się na ochronie środowisk wirtualnych, Vmware, Hyper-V, Nutanix i instancje EC2 w AWS to (były) ich specjalności, od niedawna w oprogramowaniu doszła nam jednak możliwość ochrony środowisk fizycznych, a dokładniej backup Windows Server.
Korzystając już w tym wypadku z agenta (backup dla środowisk wirtualnych nie wymaga instalacji agenta na maszynach) tworzymy pełną kopię dysków maszyny fizycznej. Możemy z niej później wyciągnąć pliki, obiekty dla MS SQL, Exchange czy AD ale również odtworzyć taką maszynę w środowisku wirtualnym. Wspominam o tym dlatego, że bazując tylko na maszynach fizycznych, prędzej lub później każde środowisko będzie migrowało się do środowiska wirtualnego, a akurat tą funkcjonalność możemy wykorzystać w tym procesie migracji jak również, aby szybko odtworzyć swój fizyczny serwer w środowisku wirtualnym bez konieczności oczekiwania na dostarczenie przez serwis jego sprzętowego zamiennika.
Zaczynamy od zainstalowania na serwerze fizycznym agenta, czyli specjalnej wersji transportera Nakivo, od tej chwili mamy możliwość realizacji zadania backupu maszyny fizycznej.
Backup maszyny fizycznej podobnie jak backupy maszyn wirtualnych trafia do repozytorium z którego możemy odtwarzać wspomniane wcześniej pliki lub obiekty podłączając ten zasób bezpośrednio do Directora Nakivo(moduł odpowiedzialny za zarządzanie całym rozwiązaniem) lub wskazanego w sieci serwera docelowego na który chcemy odtworzyć elementy. Alternatywą do tego trybu odtwarzania jest jednak możliwość eksportu obrazu dysków z formatu przeznaczonego dla maszyn fizycznych do formatów przeznaczonych dla środowisk wirtualnych jak Vmware czy Hyper-V. Takie podejście daje nam elastyczność w odtwarzaniu nie tylko środowisk wirtualnych, ale również ważnych danych na fizycznych maszynach.
Podsumowanie
Omówione mechanizmy czynią z jednej strony pracę specjalistów od backupu wygodniejszą, a z drugiej zapewniają większe bezpieczeństwo dla chronionego środowiska. Istotnym czynnikiem, który warto brać pod uwagę na etapie wyboru rozwiązania jest dostępność takich mechanizmów oraz zasady ich licencjonowania, ponieważ często to one warunkują użyteczność produktu. Decydując się na Nakivo Backup & Replication jako rozwiązanie do ochrony środowiska często okazuje się, że koszty licencji są nawet połowę niższe w porównaniu do rozwiązań podobnej klasy, z jednej strony to pozwala ograniczać koszty operacyjne, a z drugiej skorzystać z oprogramowania o większych funkcjonalnościach. W Nakivo większość elementów związanych z automatyzacją dostępna jest w licencjach typu Enterprise Essentials oraz Enterprise.
O NAKIVO
Nakivo to amerykański producent oprogramowania skierowanego głównie do ochrony środowisk wirtualnych Vmware, Hyper-V, AWS oraz Nutanix niezależnie od tego czy chcesz robić backup, replikację czy odtwarzanie całego zestawu maszyn wirtualnych, Nakivo ma wbudowane niezbędne mechanizmy do realizacji tych celów. Cechami charakterystycznymi Nakivo oprócz elastycznej, modułowej budowy są zaawansowane funkcje pozwalające oszczędzać przestrzeń dyskową jak deduplikacja, ochrona danych z wykorzystaniem szyfrowania oraz unikalne rozwiązania, takie jak Screenshot Verification czyli możliwość automatycznej weryfikacji poprawności wykonanego backupu czy VM Flash Boot umożliwiająca awaryjne uruchomienie maszyny wirtualnej bezpośrednio z repozytorium backupu, bez konieczności kopiowania jej dysków do środowiska wirtualizacji. Nakivo pomimo oferowanego ogromu funkcjonalności często okazuje się nawet połowę tańsze w porównaniu do rozwiązań konkurencyjnych dzięki czemu świetnie wpisuje się w trend ograniczania kosztów w firmach różnej wielkości.
Więcej o rozwiązaniach Nakivo, na stronie nakivo.fen.pl